Dr Andrea Zisman (a.zisman@soi.city.ac.uk)
Department of Computing, City University, Northampton Square, London, EC1V 0HB, United Kingdom
Phone: +44 (0)20 7040 8346
Fax: +44 (0)20 7040 8587
Professor Ron Summers (R.Summers@lboro.ac.uk)
Dept Information Science, Loughborough University, Loughborough, Leicestershire, LE11 3TU, United Kingdom
Phone: +44 (0)1509 223050
Fax: +44 (0)1509 223053
Stephen Katz (Stephen.Katz@fao.org), Fernando Servan (Fernando.Servan@fao.org)
Food and Agriculture OrganizationUnited Nations - WAICENT, Viale delle Terme di Caracalla, Rome, 00100, Italy
Phone: +39 06570 52299
Fax: +39 06570 54049
Dr John Chelsom (john.chelsom@csw.co.uk)
CSW Informatics Ltd, 4240 Nash Court, Oxford Business Park South, Oxford, OX4 2RU, United Kingdom
Phone: +44 (0)1865 337400
Fax: +44 (0)1865 337433
In this paper we present our experience of using Web services to support interoperability of data sources at the Food and Agriculture Organization of the United Nations (FAO). We describe an information bus architecture based on Web Services to assist with multilingual access of data stored in various data sources and automatic document generation.
The architecture preserves the autonomy of the participating data sources and allows evolution of the system by adding and removing data sources. In addition, due to the characteristic of Web Services of hiding implementation details, and therefore being able to be used independently of the hardware or software platform in which they are implemented, the proposed architecture supports the technical and organisational problems posed by the widespread use of different technologies and implementation standards in the FAO, and alleviates the difficulty of imposing a single technology throughout the organization.
XML, Web Services, J2EE, .NET, Ontologies, RDF, Topic Maps, WAICENT
The development of distributed computing and networking has provided the technological basis for remote access to data and applications. The development of different systems has increased the utility of these systems, but has not solved the problem of having a large number of applications interoperating with each other. The applications have not been built to be integrated, and therefore, they normally define different data formats, have their own communication protocols, and are developed on different platforms. Interoperability of distributed systems is still a challenge.
Nowadays it is important to allow interoperability of different types of information sources in a large company or community. Users and applications have a growing need to access and manipulate data from a wide variety of information sources. However, the data sources are generally created and administered independently, differing physically and logically. Other difficulties associated with such an environment include: heterogeneity and autonomy of database systems, conflict resolution and semantic representation of data, location and identification of relevant information, access and unification of remote data, query processing, and easy evolution of the system.
An example of the above problem is found in the Food and Agriculture Organization of the United Nations (FAO). FAO is a specialized agency of the United Nations which leads international efforts to defeat hunger. It helps developing countries modernize and expand agriculture, forestry and fisheries and ensure good nutrition for all. One of its most important functions is to collect, analyze and disseminate information to assist governments to fight hunger and achieve food security. Towards this effort FAO has established the World Agricultural Information Centre (WAICENT) for agricultural information management and dissemination.
Within the WAICENT framework, a large amount of data, represented in various distinct formats and in many different languages, are generated every day and stored in different types of data sources. People need to access and manipulate data distributed in the various sources from both inside and outside the organization. It is important to share data between systems quickly and easily, without requiring the systems to be tightly coupled. In simple terms, the existing systems need to "talk" to each other. Another main problem is related to the fact that within the organisation the use of two different technologies (Microsoft ASP and Java JSP/servlets) is widespread and it is, therefore, very difficult to impose a single technology throughout the FAO.
In this paper we present an approach to allow interoperability of the different data sources in the FAO. We discuss our experience of using Web Services to support multilingual access of data stored in various data sources and automatic document generation. The approach being proposed is lightweight and is based on the use of an information bus to allow exchanged of data between various information sources implemented by using different technologies.
The remaining sections of the paper are structured as follows. Section 2 describes the problem in the FAO that is being tackled by our approach; Section 3 presents the architecture being proposed with its various components and structures; Section 4 presents development aspects of the approach; Section 5 describes some related work. Finally, section 6 summarises our experience and suggests directions for future work.
When we started our work at the Food and Agriculture Organization of the United Nations, this organisation had approximately 200 systems supplying information for access on the World Wide Web, deployed using two different technologies: Microsoft ASP [3] and Java JSP/servlets [16]. These data sources need to share and exchange data between each other in an easy way. However, the use of the two technologies was already widespread and it was almost impossible to impose a single technology throughout the FAO. In addition, it was necessary to avoid rewriting of existing applications.
The existing information infrastructure consists of database systems containing different types of data including, but not limited to, different types of documents written in five official languages - English, French, Spanish, Chinese and Arabic (and some in Russian); electronic bibliography references; statistical data; maps and graphics; news and events from different countries; and web information. Different people generate documents in different formats, which are inserted in the databases using web interfaces. The data is accessed from the databases in HTML format.
Although the existing setting addressed some of the requirements of integrating disparate distributed systems, there were limitations involving budgetary or technical challenges, inflexibility, lack of standardisation, and difficulty of scalability. It was important to have a technology that is inexpensive, easy to implement, easy to maintain and based on open standards, to allow leverage of knowledge and existing resources without having to rewrite existing applications.
The technology needs to support interoperability of existing data sources and management of multilingual variants without changing the database structures. Currently, it is necessary to customise and add database structures for each different language. There is no standard way to manage language variants of documents or other data structures. This generates inconsistencies between applications in the way that they manage the different languages. In addition, the database models are not easily extensible when new data or language variants are added.
Other problems were related to the support of meta data representation and meta data exchange in a standard way, as well as use of standard ontology formats. In the FAO a document repository has been developed with the objective of storing and disseminating all publications electronically. It stores meeting notes, documents, meta data and index data. Different ASP interfaces have been created to allow searching the document repository by type, language, and subject. However, there is no standard way to manage language variants of documents or other data structures. FAO's multilingual Agricultural Thesaurus (AGROVOC) has been applied to the web as a strategy to ensure some conformity in resource description/discovery but falls short of being an complete tool for this purpose in view of a need for more specific subject terminology and richer ontological relations than are offered by a traditional thesaurus.
In this section we describe the architectural approach that was developed to deal with the above problems - the next section describes how the approach was implemented in practice. The main aim of our approach is to allow interoperability between existing data sources in the FAO, in a way that can be implemented on multiple vendor platforms, with minimal effort and disruption to existing systems. The approach needs to support the multilingual characteristics of an institution like FAO, in which documents are expressed in the five official languages (English, French, Spanish, Chinese, and Arabic) as well as Russian and other local variations.
The principle objective of the approach is to create an environment where new web-based information systems can be developed quickly and easily, using any technology platform, by accessing information from any of the existing information systems at he FAO (there are about 200 of those). This approach has been proven in a prototype development which aims to:
Create a generic XML-based information infrastructure to support multilingual information in an extensible and standard way.
Create an application integration structure based on Web Services to allow interoperability of FAO systems and information sources for delivery through web portals.
Compare the use of different Web services technologies: Microsoft .NET and J2EE.
Demonstrate standard XML representations for handling meta data and multilingual documents.
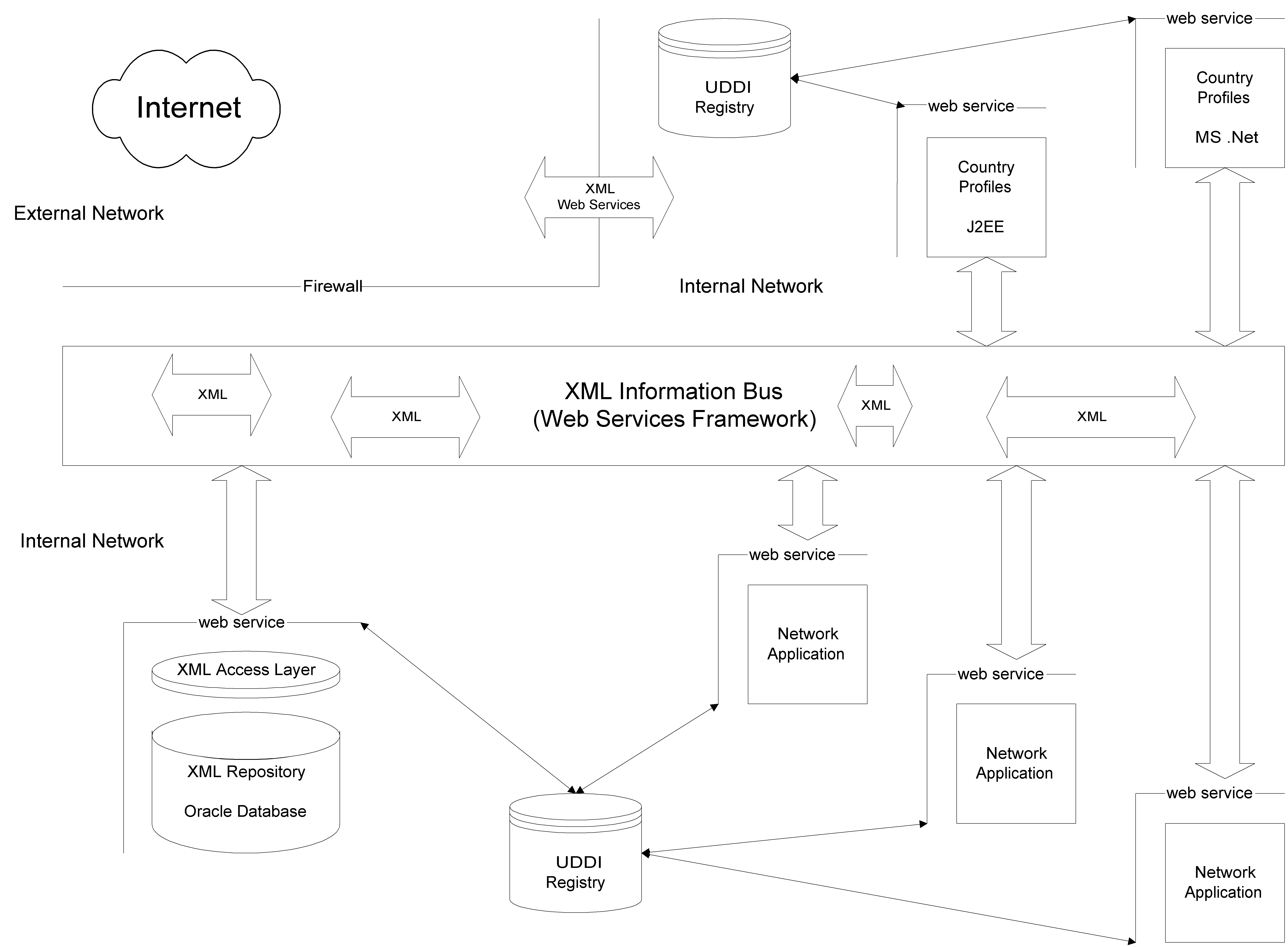
In order to achieve the aims and objectives above we proposed a simple and lightweight architecture based on Web Services technologies and XML. Figure 1 presents an overview of the architecture with its various components. The architecture consists of an information bus in which information passes as XML structures. The different data sources are wrapped with Web services interfaces in which information inputs and outputs are passed also as XML structures. With the Web Services it is not necessary to re-engineer existing systems to new XML standards. However, it is necessary to enforce XML standards in the Web Services interfaces. For instance, the parameters for operations involving language codes always use the 2-character ISO 639 code.
The management of information, including handling of multilingual variants is based on XML. We propose to move structured information out of database fields and represent them in XML documents to allow a more generic model, which is easier to administer and to extend to new languages (e.g. there is a growing need to support Russian, in addition to the five existing official languages). Whereas existing systems use their own (non-standard) database structures to model multilingual data, the XML approach provides a generic way to manage structured information (to any schema)
The handling of meta data is also based on XML (using RDF [17], RDF Schema [4] and XML Topic Maps [22]), which can be used as the exchange model throughout the FAO. The assignment of constraint meta data is based on standard ontologies published or developed in-house, also represented in XML. This facilitates importing and exporting of all XML meta data held in participating systems.
The FAO currently has a web application called FAO Country Profiles [11], which draws information from a variety of systems on the internal network and presents an aggregated view, sorted by country. Within each country profile, information is structured according to the main functional areas of the FAO - Sustainable Development, Economic situation, Agriculture sector, Forestry sector, Fishery sector, Technical Cooperation.
We proposed the development of two (functionally) identical applications for the Country Profiles, but using two different Web Services technologies - Microsoft .NET [21] and J2EE (from the Apache Software Foundation [2]). The objective was to show that regardless of the technology platform used, Web Services could be used to integrate rapidly data extracted from any of the FAO systems.
The architecture contains two UDDI registries to support discovery of information. One UDDI registry is internal to the FAO and assists with share and exchange of information between the data sources internal to the organisation. The other UDDI registry is used to support share and exchange of data between the data sources external to FAO.
This section describes how the technical approach was implemented in an operational prototype system between January and April 2002. There were three main activities in the development:
Creating Web Services ëwrappersí to existing applications, so that they could be accessed through the XML Information bus
Implementing a new XML document repository that allows structured data to be stored for different languages in a generic and extendible manner
Implementing the Country Profiles application as both a MS ASP and a J2EE application, calling the same set of Web Services to access data from the existing systems
Web Services wrappers were developed for three types of system:
Internal to the FAO, for which the development team had access to the application source code
Internal to the FAO, but the development team had no access to the application source code
External to the FAO
In all, Web Services wrappers were created for the following systems (those already accessible from the web are listed with their URL):
The concept of the XML Information bus is that all data passes through it in standard XML formats. These formats can be imposed in a regulated fashion by publishing the XML schemas used and validating instances of messages. Regardless of the formats used by the existing systems, the same XML syntax is used for input and output parameters on the Web Services. For example, all data related to country, language or currency is represented in a single XML format which uses:
Behind the Web Services wrappers, the existing systems handle country, language or currency in many different ways (some following recognized standards, others not). The logic of transforming from the standard XML representation used in the input parameters of the Web Service, to the internal representation of the system is implemented in the Web Service itself.
For existing Microsoft applications, to which the development team had access to the source code, one great advantage of the .NET framework was the ease with which Web Services wrappers could by created. However, these Web Services did not integrate with the J2EE platform without some problems.
At first there were problems integrating .NET Web Services with J2EE Web Services. This is because .NET uses Document-style web services by default, whereas the J2EE implementation (Apache Axis) uses RPC-style invocation. To alleviate this problem in .NET we used the SoapRpcService() property to indicate that the .NET web service was RPC-style. However, there were further problems because Axis did not yet implement support for multi-dimensional arrays or for generating complex type definitions in WSDL, which were created automatically by .NET.
To alleviate this problem, and to allow developers to create Web Services quickly and easily from existing Microsoft applications (of great importance to FAO, to encourage all departments to make their applications available as Web Services), a second tier of Web Services was created that automatically made the transformation from the data types generated by .NET to XML arrays that could be used by both .NET or J2EE Web Services.
As well as the Web Services wrappers, a new XML repository was implemented to store XML documents and meta data in multiple languages, in a way that could easily be extended (e.g. to add another language). This XML repository stores resources (documents) in a standard relational database, following an extended version of the XML:DB API [29] that caters for document variants (e.g. different language variants of the same document) and meta data associated with documents.
The XML repository uses RDF, RDF Schema and XML Schema for the following purposes:
RDF specifies meta data on resources (i.e. values of properties for the resource)
XML Schema defines vocabularies of allowable values (range of values) that a property can take
RDF Schema defines classes of resource and the properties (meta data slots) that instances of each class can take
RDF Schema and XML Topic Maps define ontologies which capture the relationship between classes, resources and properties that make up a vocabulary
The XML repository was itself wrapped as a Web Service so that documents could be accessed by meta data and/or language from the Country Profiles applications.
The challenge of interoperating distributed systems, in particular database systems, has existed for a long time and has been extensively researched. Many approaches have been proposed to allow integration and interoperability of distributed systems developed in an independent way. These approaches have been proposed as outcomes of research work in both academia and industry.
We can divide the existing approaches into two main groups. In the first group of approaches a global schema is used as another layer on the top of existing schemas which gives the users and applications the illusion of a single, centralized database system.Ý Examples of these approaches include systems like DATAPLEX [6], DDTS [9], MULTIBASE [25], and PEGASUS [1].Ý However, the construction of a global schema is not a simple task, does not guarantee the autonomy of the participating database systems, and does not allow easy evolution of the system in terms of adding and removing of participating databases.
In order to overcome the problem of constructing a global integrated schema the second group of approaches has been proposed, in which ëpartialí or ëno integrationí is performed. Examples of these approaches include the federated architecture [15], multidatabase architecture [18] and the Jupiter system [14]. Within the approaches that do not use a global schema some of them proposed the use of mediators and wrappers. In these approaches data sources are encapsulated to make it usable in a more convenient manner by hiding or exposing the internal interface of the data sources, reformat data, and translate queries. Examples of systems that use wrappers and mediators are DIOM [20], DISCO [28] and TSIMMIS [12].
In any of the above approaches and existing technologies the problems related to how to format data to be exchanged and how to transmit the data are still open problems. Regarding data format, there are almost no tools that can automate the process of translating data in different formats. Many systems use ASCII-based text files to represent their data. However, there is no standard way of formatting or describing the values in the files. The different systems exchanging data in ASCII format must have custom-built loading software to handle different file formats. Other systems exchange data via a specified file format, which does not scale well (e.g. Microsoft Excel).
On the other hand, data transmission has also been difficult to implement. The use of the File Transfer Protocol (FTP) facilitates file transfer, but this is not a tight, object-oriented approach to exchanging data. Electronic Data Interchange (EDI) [10] has also been used for exchanging data. However, EDI is rigid, complex, and expensive to implement. More recently some technologies have been proposed to allow a more object-oriented and less expensive approach, based on Remote Procedure Calls. Examples of these approaches are DCOM [8] and CORBA/IIOP [7]. The problems with these technologies are that they are platform specific, do not easily integrate, and pose network security risks due to the requirement of having open ports to accommodate messages.
The existing approaches have contributed to alleviate the problems of sharing data between autonomous and heterogeneous data sources. However, the development of Web Services [13], SOAP [5], and XML technologies support the problems of e-business by allowing the ability of representing data structures and describing these structures in an easy way to implement and maintain.Ý
We presented an approach to allow interoperability of different data sources containing distinct types of information expressed in different languages. In the approach we propose to use Web Services to support many of the issues related to interoperability of different systems, developed on different platforms. Our experience has been very positive. We have found that it is very easy to develop the wrappers around the data sources. Some of the activities have been implemented in hours, instead of days as it was initially planed.
The GUI of Microsoftís .NET is very intuitive and facilitates the development of Web Services from existing Microsoft applications. It was not possible to directly integrate .NET Web Services with J2EE Web Services, due to difference in handling complex data types and inconsistencies in the use of WSDL. However, it was possible to integrate Web Services from the different platforms by writing simple, generic wrapper services which provided a consistent implementation using SOAP-RPC. In addition, the approach allows the sharing, exchange, and merging of data in a way that it was not possible before.
Based on the experience with this information bus we expect to be able to use the approach in other situations in which it is necessary to interoperate distributed systems. The Web Services technology has enabled the integration of systems in a way that was not possible before.
We would like to thank all members of the WAICENT/FAOINFO Dissemination Management Branch team at the Food and Agriculture Organization of the United Nations. Giorgio Lanzarone, who acted as the project coordinator in FAO, and Marta Iglesias, Nick Waltham and Anne Aubert for participating in the requirements specification phase and developing the Web services wrappers in the data sources of FAO. We would also like to thank some members of CSW Informatics. Mavis Courname for participating in the requirements specification phase. Niki Dinsey and Stephen Horwood were responsible for the implementation of the country profiles applications, Web services client wrappers, and XML repository.
[1] R. Ahmed, J. Albert, W. Du, W. Kent, W. Litwin, and M.C. Shan. An Overview of Pegasus. In the 3rd International Workshop on Research Issues and Data Engineering: Interoperability in Multidatabase Systems, pages 273-277, Vienna, Austria, April 1993. IEEE Computer Society Press.
[2] Apache. Apache Project. http://www.apache.org
[3] ASP. Microsoft Active Server Pages. http://www.microsoft.com/asp
[4] D. Brickley and R.V. Guha. Resource Description Framework (RDF) Schema Specification 1.0, March 2002. http://www.w3.org/TR/rdf-schema
[5] D. Box, D. Ehnebuske, G. Kakivaya, A. Layman, N. Mendelsohn, H. Nielsen, S. Thatte, and D. Winer. Simple Object Access Protocol (SOAP) 1.1. http://www.w3.org/TR/SOAP.
[6] C. Chung. DATAPLEX: An Access to Heterogeneous Distributed Databases. Communications of the ACM, 33(1):70-80, January 1990.
[7] CORBA/IIOP. Common Object Request Broker Architecture. http://www.omg.org/technology/documents/formal/corba-iiop.htm.
[8] DCOM. Microsoft Distributed Component Object Model. http://www.microsoft.com/com/tech/DCOM
[9] P.A. Dwyer and J.A. Larson. Some Experiences with a Distributed Database Testbed System. In Proceedings of the IEEE, volume 75, pages 633-648, May 1987.<
[10] EDI - Electronic Data Interchange (See http://www.diffuse.org/edi.html)
[11] FAO Country Profiles and Mapping Information System. http://www.fao.org/countryprofiles/
[12] H. Garcia-Molina, Y. Papakonstantinou, D. Quass, A. Rajaraman, Y. Sagiv, J. Ullman, V. Vassalos, and J. Widom. The TSIMMIS Approach to Mediation: Data Models and Languages. In Next Generation Information Technologies and Systems (NGITS), Naharia, Israel, June 1995.
[13] S. Graham, S. Simeonov, T. Boubez, D. Davis, G. Daniels, Y. Nakamura, R. Neyama. Building Web Services with Java: Making Sense of XML, SOAP, WSDL, and UDDI. SAMS Publishing, 2002.
[14] J. Grimson and J. Murphy. The Jupiter Approach to Interoperability with Healthcare Legacy Systems. In R.A. Greenes, H.E. Peterson, and D.J. Protti, editors, MEDINFO 95, pages 367-371, IMIA 1995.
[15] D. Heimbigner and D. McLeod. A Federated Architecture for Information Management. ACM Transaction on Office Information Systems, 3(3):253-278, July 1985.
[16] Java. Java Java Server Pages/Servlets. http://java.sun.com
[17] O. Lassila and R.R. Swick. Resource Description Framework (RDF) Model and Syntax Specification. February, 1999. http://www.w3.org/TR/REC-rdf-syntax.
[18] W. Litwin. From Database Systems to Multidatabase Systems: Why and How. In W.A. Gray, editor, Proceedings of the 6th British National Conference on Databases (BNCOD 6), British Computer Society Workshop Series, pages 161-188, July 1988.
[19] W. Litwin, L. Mark, and N. Roussopoulos. Interoperability of Multiple Autonomous Databases. ACM Computing Surveys, 22(3):267-293, September 1990.
[20] L. Liu and C. Pu. Dynamic Query Processing in DIOM. Bulletin of Technical Committee of Data Engineering, 20(3):30-37, September 1997.
[21] .Net. Microsoft .Net. http://www.microsoft.com/net
[22] S. Pepper and G. Moore. XML Topic Maps (XTM) 1.0. http://www.topicmaps.org/xtm/1.0.
[23] M.T. Roth and P. Schwatz. Donít Scrap It, Wrap It! A Wrapper Architecture for Legacy Data Sources. In Proceedings of the 23rd International Conference on Very Large Database Bases, Athens, Greece, August 1997.
[24] A.P. Sheth and J.A. Larson. Federated Database Systems for Managing Distributed, Heterogeneous, and Autonomous Databases. ACM Computing Surveys, 22(3):183-236, September 1990.
[25]J.M. Smith, P.A. Bernstein, U. Dayal, N. Goodman. T. Landers, K.W.T. Lin, and E. Wong. Multibase - Integrating Heterogeneous Distributed Database Systems. In National Computer Conference, volume 50 of AFIPS Conference Proceedings, pages 487-499, 1981.
[26] SOAP-RPC. http://www.soaprpc.com.
[27] G. Thomas, G.R. Thompson, C.Chung, E.Barkmeyer, F.Carter, M.Templeton, S. Fox, and B. Hartman. Heterogeneous Distributed Database Systems for Production Use. ACM Computing Surveys, 22(3):237-266, September 1990.
[28]A. Tomasic, L. Raschid, and P. Valdueriz. Scaling Heterogeneous Databases and The Design of Disco. In Proceedings of the 16th International Conference on Distributed Computing Systems (ICDCS), pages 449-457, Hong Kong, May 1996. IEEE Computer Society Press.
[29]XML:DB. http://www.xmldb.org.
[30] A. Zisman and J. Kramer. An Approach to Interoperation between Autonomous Database Systems. Ý Engineering Journal, 6, 1999.
[31] A. Zisman. Information Discovery for Interoperable Autonomous Database Systems. PhD Thesis, Department of Computing, Imperial College of Science Technology and Medicine, University of London, UK, 1998 (http://www.soi.city.ac.uk/~zisman)