This paper describes how combining high quality resource description with a web crawler using simple Dublin Core and the RDF model created a novel search system for the teaching, learning and research communities that is now being deployed as a service. The prototype gave the major benefits of both - returning high quality resources as well as timely and more widespread resources. It provided new features such as presenting the provenance of the discovered resources, improving cross-subject area discovery and was capable of integrating well with other emerging semantic web systems such as web page annotations.
The UK digital library community has a long experience in producing subject-specific information services for the higher education community. These services, which are called Subject Gateways, can be considered portals to high quality online information in their various subject areas. The resources for these services are typically picked and selected by domain experts or library professionals with extensive experience and training on selecting quality resources.
These web resources have usually been made available by subject-specific, or vertical, services; although recently these some have started to have been integrated into larger Hubs which are groups of related subject areas, for example social sciences. The remit of these larger services has expanded and they have taken on the responsibility to support additional groups such as further education, non-traditional learners, online teaching and learning, usually with the same resources.
The services must be improved to match the growing number of users and their changing needs - new subject areas, wider coverage of web resources and timeliness of search. There are many valuable online resources that could be used however even for an information processional, finding the best ones is a problem and describing them well such that they can be discovered by users is difficult.
These resources have to be able to be found using simple, familiar interfaces and the ones that are increasingly more familiar to users are web search engines. Traditional subject gateway interfaces come from the digital library world and have a more catalogue-based interface. Experience from user testing of web search systems show[1] that most users type a few words (2-3) into the search box and very few use the advanced search options that are available (boolean searches, fielded searches etc.).
The subject gateways need to be kept up-to-date with the resources on the web and cover all the subject areas that users require - including cross-domain areas. This may mean that some resources might fall between multiple services and hence not be catalogued. For new and cross-domain subjects, important resources could therefore be missed.
Through all of this, the resources catalogued must be kept to a high quality such that the services can maintain their professional standard and thus their reputation. These need to be appropriate for the subject areas, and carefully selected from the vast array of information of the web by experts, assuring that the service can maintain its trust relationship with the users.
In this section we review the two main systems used in the digital library community to describe and locate resources on the web.
Subject gateways come from the digital library community and are based on the cataloguing model and practice, with formal rules for the collection policy of the service operated by professional cataloguers or trained domain experts. The gateways generally use a database to store the records describing the resources, and the descriptions can vary in richness from simple to very detailed. The resource metadata is generally quite a flat format; multiple key and value pairs of information about the resource; there are not usually many references between records. The gateways mostly support at least the Dublin Core Element Set (DCES)[2] and depending on the subject area can extend to very detailed descriptions, using rich cataloguing standards such as UNIMARC[3] and Dewey[4].
The discovery and selection of the resources is time consuming and involves analysing the appropriate level to catalogue - the granularity of either describing, for example, web pages, part of a web site, a whole web site, or a combination of these. The discovery of appropriate resources is done by using existing domain knowledge, evaluation of publications and use of web searching[5]. The latter needs extensive experience in using online web searching systems such as Google[6] in order to locate information in the rapidly growing web space. Other methods are used to capture topical information such as mailing lists, web sites that update news on the topics, news alerting sites and more general news services.
The subsequent creation of the catalogue records describing the resources requires extensive time and thought by the cataloguer and consideration of many aspects in order to produce a high quality description. The cataloguing rules must be carefully followed using appropriate terms from the domain, cataloguing standards, dictionaries and thesauri and writing short descriptions to be read by people describing the resource. This requires use of cataloguing tools, reference works and knowledge of the policies and cannot be automated in most respects since it relies on judgment and analysis. Human cataloguing is good at identifying, for particular topics, the best authoritative sources and the best hub pages (pointers to these good authorities)[7] since the pages themselves may not include the search terms that describe the topic, which people would typically search for if they are familiar with the terms in the subject area
This process of producing high quality records is thus very time consuming and the records cannot be expected to describe all of a site, given a particular granularity has to be chosen. The records are written at a certain time and have to be reviewed later in order to ensure that they are up-to-date. This review usually takes place after a year or more, so cannot pick up changes in faster-changing web sites, which can be the most interesting ones. The number of records that can be written is thus rather small compared to the size of the web so that searching subject gateways can return zero hits, either when the topic is not found in the known keywords, is a topic that appeared after cataloguing, was not yet catalogued, was missed or was cross-domain and fell between two subject areas covered by different subject gateways.
Web crawlers are software systems that use the text and links on web pages to create search indexes of the pages, using the HTML links to follow or crawl the connections between pages. Web crawlers such as Google use the link structure along with the words on the link label to indicate the relevance of the pointed page, similar to the citation model of references in academic papers. This algorithm calculates a value for each page called PageRank[8] which is used in querying to help with working out the relevance of search terms with web pages.
Since they are software systems, web crawlers run at computer speeds and can fetch many pages from web servers, limited only in how often it is friendly to fetch pages from the web server (once a minute is accepted) rather than any particular restriction of the software. The web crawlers take the pages and word-index them, using the markup on the web pages as hints to the relevance of particular words and phrase - more prominent and larger text getting a higher value. The indexing and searching algorithms and optimisations employed on pages are closely guarded by the search engine vendors, especially to prevent keyword spamming of pages using popular search terms for diverting users to irrelevant pages.
The vast size of the web means that major computer systems have to be constructed to run these services and this tends to be done by a small number of very large centralized computer systems which can handle the enormous data size and computing requirements. These services get good results only as long as they have a coverage of a large part of the total web; even if some part of the resulting crawled web is thrown away and not used in the search index. PageRank mentioned above works best when it crawls a large part of the web since the algorithm used is an approximation to the web link structure that improves as more of the web is crawled.
Many algorithms[5]
are available for computing ranking for
web-based searches using classical techniques or web-specific ones,
but all they have to use is the structure of the web formed from
HTML anchor tags:
<a href="http://example.org">link text</a>
and all that indicates is that one page is linked to another; not
that there is any relationship between them. In particular
the link text might be "is a terrible page"
so using this link to infer that the two pages have a reinforcing
relation would make the search results worse. The standard links
between pages in HTML describe a general relation is-linked-to with
no more specific semantics, rather than see-this-great-page,
see-this-related-page or see-this-terrible-page. (There is
a technology called XLink[9]
that can allow typed links to be added to HTML).
The results of a query on a web search is a sequence of web pages in some order calculated by the ranking algorithm along with the heuristics that may be applied by the service. There is no way for users of the service to determine what this order means since the indexing methods are a valuable asset of the search service, so the returned results have to be trusted by the user as legitimate given the keywords. Web search engines are good at finding highly referenced pages, which might be authorities in the terms of [7] or just very general sites such as directories or home pages since the web search systems cannot distinguish between these with only a simple reference count. The web search systems cover the entire range of topics on the web and so are not optimized for particular subject areas, and can only use what the authors describe on the page which may not be entirely related to the kind of keywords that the users may search on (even given search engines use of thesauri).
The remainder of this paper describes the WSE project that was designed to combine web searching and high-quality human-written descriptions in order to gain benefits from both and make possible some novel applications, for the education, teaching and research communities in a selected set of subject areas. Experiments have been conducted before combining web searching with subject gateway records in [10] but took more of a cross-searching approach over separate search systems. Other work has been done on more focussed web crawling by choosing different ways to do the crawl[11], or gathering and crawling metadata. This project was designed to work on the benefits of combining web pages and high quality records with provenance tracking, which has not been done on this scale before. For this project, records were used, with the kind permission of the owners, from the following subject gateways:
In order to connect the subject gateway records to a web crawling and search system, the URI of the web page resources in the records were extracted. The records also have their more rich descriptions available from the original descriptions written by the subject gateway cataloguers. In order to make these available in a uniform way for simple resource discovery, selected fields were taken corresponding to a subset of the DCES. Table 1 shows the Dublin Core elements and values that were used as the most appropriate and minimal properties for describing web resources.
| Dublin Core Element | Description |
|---|---|
| Title | A name given to the resource |
| Description |
An account of the content of the resource |
| Identifier |
An unambiguous reference to the resource within a given context |
| Source |
A Reference to a resource from which the present resource is derived. |
In this system the description value is the high quality description written by the cataloguer, the source element is the identifier of the record from the original subject gateway site and the identifier is the URI of the resource itself.
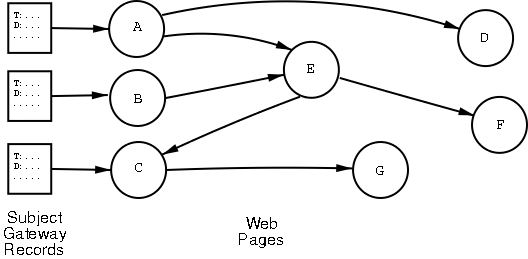
Figure 2 shows how the subject gateway records provided the URIs which were used as starting addresses for a web crawl, giving initial web pages A, B and C. This web crawl has to preserve the provenance of the information so that this could be made available later to the user. This meant it needed to record the relationship to the original source of the description - the specific record used, and the subject gateway that provided it - in order that the link could be preserved on subsequent web pages found from a crawl. For example web page G was found from subject gateway record C and thus the step from C to G must record that G ultimately was provided by the subject gateway that described C. In addition, when multiple pages were pointed to by different subject gateway records, or by other web pages, this also had to be preserved and tracked so that all influences or references to results were available to the system. For example, web page E was found via two web pages A and B but must reference to the original subject gateway records that described A and B.
The results of this web crawling system would be a web of results, that is, a large directed graph of links from subject gateway records to web pages, onwards to other web pages, where the links would be rather rich in including the information on the way that the crawl was performed. Each node in the graph would be a resource description identified by a URI either provided by the original subject gateway record or extracted from the text of the web page. The resulting graph was thus going to be very complex, large and had to be easy to manipulate and access efficiently for web-sized data.
This directed graph labelled with URIs and the use of simple metadata indicated that the appropriate technologies to use were the DCES for the descriptive terms, and the W3C Resource Description Framework (RDF)[12] as this web metadata format was designed to model information as directed graphs.
The components of the WSE system are a web crawler, an RDF system to store and query the graph of resource descriptions and an indexing system to allow full-text queries of the resource properties and values in order to return a ranked result set of resources. The system inputs were simple Dublin Core records containing the elements described above as a set of records for each subject gateway. These records were provided in various formats and converted to RDF/XML on import.
The Combine[13] web crawler system was chosen as an easily available Open Source system that had already been used for multi-million web page searches for the Nordic Web Index (now closed). It was written in Perl and thus easy to modify to handle the updated provenance tracking. Since it allows the customisation of the harvested web page storage format, it was also easy to change the storage of the web pages to be RDF/XML.
Combine did no tracking on the provenance or history of the links back to the original URI that it came from. This was required to be added as well as the details of the original record and allowing to there may be many source web pages and records at different distances back in the web crawl. This was a substantial and pervasive change to all parts the web crawler.
The general operation of Combine was by creating and emitting various text file formats containing URLs with various fields such as last-modified, storage keys etc. and using these to pass on various stages of the web crawl. These formats were all modified to carry forward the additional provenance tracking information that were required; a list of the following items:
The existing web crawling software already handled extracting various parts of the web page content such as any embedded DCES metadata, title, headers, outgoing links etc. and the words on the page into a general descriptive content field. The title and content parts would generate Dublin Core title and description element content respectively for the web pages records, which would be identified with the URI of the web page in the storage systems.
The RDF/XML records encoding the four elements mentioned above, along with their values, were available for each web record as well as for each subject gateway record. The formats were designed to be compatible such that they could be indexed together using the same full-text search system so that when a query string was given to the search system, it returned the URIs of the records that most closely matched the query. The indexed fields were the title and description either from the information stored in the subject gateway records or in the web pages. Additionally, when indexing web pages that were directly linked from subject gateway records, the title and description fields from these records were used to index the web pages.
The full-text search wasn't involved in record retrieval since it didn't have any knowledge of the complex representation of the graph structure that the individual records formed with the web crawling and provenance. The RDF storage and query system described in the next section was optimized for that.
Each of the subject gateway resources and the web pages found by crawling were identified by URIs for the internal records in the system. These are the RDF resources in the system and have properties for storing the DCES elements, the link relationships and other information as gathered during the web crawl. It was expected that there would be around 2-300,000 web pages generated from approximately 30-50,000 subject gateway records. Each of these web pages would have several properties so that the resulting number of arcs in the graph would be around 2-3 million.
RDF graphs are made from triples of source node, property arc and object node as shown in Figure 2. These needed to be indexed efficiently such that it was easy and quick to add the triples to the graph, and to query the resulting graph for matching triples. The Redland[14] RDF system was created for this project to provide this efficient RDF storage and querying, giving a high-level interfaces in Perl (and other languages) for applications. Redland provides storage for large RDF graphs with indexes that allow the most common querying to work efficiently.
For this application there were two main queries that had to be handled, in terms of RDF triples. They are given below in the (subject, property, object) format; with <u> for URI u, "x" for the string x and ? to denote a value being queried for. URIs are abbreviated to prefix:localname in the style of XML elements.
The first query is when given a URI of a resource, find the value of a given property for it. This corresponds to, for example, finding all Dublin Core title element values title-value in the graph matching the following triple:
<resource-uri> dc:title "?title-value"
The other common query is looking up the provenance information for a resource with some URI resource-uri by looking up the WSE incoming links property
<resource-uri> wse:inlinks <?inlinks-uri>
and then using that inlinks-uri to navigate to the attached RDF bag of incoming-links and their properties like this:
<inlinks-uri> rdf:Bag <?bag-uri>
<bag-uri> rdf:_1 <?link1-uri>
<link1-uri> wse:hops "?hops-value"
<link1-uri> dc:source <?source-uri>
...
which returns a list of incoming links with parts (hops count, source URI, ...). Each of the triple queries above was a separate query to the database; Redland did not provide a query language that allowed conjunctive querying of all the results in one request.
The WSE project is composed of the three main parts - web crawler (Combine[13]), full-text indexer (Zebra) and the RDF database (Redland[14]) as well as the user interface to the search. The system is driven from the subject gateway records which are imported at different times. These are then converted to a simple Dublin Core in RDF/XML format and imported into the web crawler as seed URLs. The web crawler is given this list of jobs and starts the crawling, creating new RDF/XML records for each web page and a new list of jobs recording the web crawling link details. This new list of jobs can then be re-fed into the web crawler to go a further hop into the web, but is usually pruned in some fashion to restrict the work. For this project only 2 hops were done from the original record in order to preserve the close relationship to the original record and to keep the size of the data manageable with the available tools.
Once the web crawler had created the web crawl RDF/XML records, these were then be indexed along with the original RDF/XML subject gateway records. Redland RDF databases were created for the link graph information and the subject gateway record information and the full-text indexer was run on the same records to allow a textual query of the property values to indicate relevant records.
The resulting indexes were then ready for use by the search interface. The search program takes a simple string query from the user (and possible selection of one of title, description fields) and then passes that to the full-text indexer. This returns a sequence of results in a relevance ranking order; as mentioned above, for the web pages linked near the subject gateway records, this includes the text from the original record description. A simple search interface was created that showed the provenance information for each search result; the original subject gateway, pointers to the record and details of how far away it was.
| Subject Gateway | Records |
|---|---|
| BIOME | 7568 |
| Bized | 2629 |
| EEVL | 6484 |
| SOSIG | 10319 |
| DutchESS | 5306 |
| Total | 32306 |
The project took subject records from 6 different subject gateways as shown in Table 2. These were used as the starting records (after filtering out some that we were not possible to crawl with this software such as https:, mailto: and gopher: URIs). After web crawling this resulted in a total of 360,118 web pages (3.6GB) as well as the subject gateway records (2MB) which were indexed to give 1.5GB of full-text indexes and 2.3GB of Redland RDF graph databases. The most time consuming part of the work was the web crawling which took several weeks to complete for all the larger and slower sites, fetching at most 1 page per minute. The indexing process was possible to complete in a single day although could have been done incrementally as the records were added. Subsequent changes to Redland now allow dynamic updates to the RDF databases.
The searching system using the full-text searcher and the Redland RDF databases was run on-the-fly making connections to the search system on demand and opening the database files on disk at request time. As an experimental system, this was deemed acceptable as a first attempt to demonstrate the system. However, the performance of this search proved very good; the full-text search system returned the URIs for the RDF system very quickly and the multiple queries (100s per page) to the RDF databases operated in fractions of a second and thus the user response to a typical query was well under 3 seconds
The user interface for this search system was a simple text box with a choice of the few fields to search over (Title, Description, both) and a submit button. This was designed to look more like a web search engine than a catalogue search so that it was a familiar interface.
Figure 3 shows one search result for a search on sociology timeline with results from both the web and cataloguing. The result is presented with the title and URI followed by a list of the references to the page. The first reference here is to the direct cataloguing of the page in a SOSIG record; the second is a link from a web page catalogued by a different SOSIG record. Finally the description of the result is given, not from the web page but is the human-written description, with a link to the full record (more..) if that was required. All of the information above was pulled from the RDF databases using queries like those described in Section 4.3; and indeed further information is also extracted and encoded as link "pop-ups" so that the title of the referred records and web pages are also available. The final links SOSIG description and more... go to the original subject gateway record where the full record is available, allowing use of the subject gateway search systems and browsing; in this case, browsing into sections on Sociology and Sociologists.
| 1. | Transgenic Crops: Benefits and Risks | Web page crawled from a record catalogued by BIOME |
| 2. | Belgian Biosafety Server | Record catalogued by BIOME |
| 3. | [AGBIOS INC.] News Story | Web page crawled from a record catalogued by DutchESS |
| 4. | Essential Trading - Organic, GMO Free, Fair Trade, and Vegetarian Wholefood Co-op | Web page crawled from a record catalogued by Bized |
| 5. | UK Department of the Environment, Transport and the Regions | Web page crawled from a record catalogued by BIOME |
| 6. | AgriBiz Articles and Trade News | Web page crawled from a record catalogued by Bized |
| 7. | Biotechnology | Web page crawled from a record catalogued by DutchESS |
| 8. | New audio tape on Genetic Engineering | Web page crawled from a record catalogued by SOSIG |
| 9. | EU Summit in Nice - What kind of Europe do we want? | Web page crawled from a record catalogued by SOSIG |
| 10. | Natural Law Party | Web page crawled from a record catalogued by SOSIG |
Figure 4 shows the results of searching the system for "gmo" returned a range of results from Biome, DutchESS, Bized and SOSIG related to Genetically Modified Organisms. The results show that the of the top ranked results, the majority of them were not originally catalogued by the services and give results in this cross-domain topic covering its social, commercial, science, technological and political impact which probably would not be picked up by the original services. More general search engines would not necessarily pick up these pages as related; trying this out with some general search engines mostly returned organisations titled GMO in the first 10 with a minority of related results.
A further example of WSE search results compared to both general search engines and subject gateway search engines is a search for the terms "game theory napster". This is the combination of a search for a theory well known in economics - game theory - along with a much newer peer-to-peer system called Napster. The former has been catalogued in various business and social science subject gateways and searching for "game theory" on those sites (SOSIG and Bized for example) returns hits of quality resources for game theory. However, searching for "game theory napster" returns no hits on any of those sites. WSE did return relevant results for this query in two ways. Firstly it picked up the term from a web page already catalogued by SOSIG; where the term napster appeared on the web page but not in the catalogue description. Secondly the page about the topic "Why Napster is Right" was found directly by web crawling from pages related to game theory. The general search engines may have found the latter; but not the former as a quality selected site. The subject gateway search engines would have not returned either unless the existing catalogued page had been reviewed and updated to the new topical term.
The final type of search that WSE can perform is to query for the URIs themselves. Since the system is based on URIs for identifiers, any web page can be looked up by its URI and the related pages shown. This presently means showing the entire incoming links or references from subject gateways and can be used to gain a view on how the page in question relates to its neighbors. This is a way that the user can use the search result to find out more, related pages; with the provenance displayed as above, indicating where the incoming pages were cited, and what their relevance is.
The existing crawling goes a few hops from the starting URIs but this could be more selectively done; working out quality sites to look at more deeply, selecting links by domains since in this community, academic and educational sites are more easy to identify. The crawling could be improved to extract some of the keywords in the web pages to try to work out the topic using automatic classification or natural language processing. The distance of the page from the original record could be involved in the ranking of pages. The words on link anchors could also be used to index the destination pages; these are already recorded but not at present added to the full-text indexing.
Some work has already been done on evaluating the current interface which was designed to show all the information, rather than be particularly easy to use. This involves adding icons to the output to indicate the type of resource - web page or human-written description. Other changes could be done such as allowing ranking by subject gateway and links to browsing related topics in subject gateways if the simple 4-element record was expanded to include some additional DCES elements.
This is a Semantic Web system; it knows about nodes with URIs and properties of those nodes also with URIs. It would be easy to add information from other such systems, based on this model. These could include RSS 1.0/RDF[15] news feeds from other content providers, indexed with the existing records and appearing in the results. The MedCERTAIN[16] project uses PICS/RDF annotations of web sites to positively identify high-quality medical information. These trust-marks could be looked up and displayed for web sites that matched, or used to influence the ranking of the search.
The WSE system is being deployed as a search system for the UK Resource Discovery Network (RDN)[17], using the subject gateways or hubs that comprise it. This was using the existing model, with the initial metadata collection done by the Open Archives Initiative (OAI)[18] protocol which is already being used by the RDN to collect the simple records for other purposes.
When the two systems are joined, the subject gateways cataloguing is essentially extended to cover larger parts of the web, be more up to date (automatically). The prototype system has decreased the number of search results that give zero hits and has extended the subject-specific gateways outwards towards related subject areas hence benefiting cross-domain areas. Compared to web search systems, it gained higher quality description and hence relevance as well as benefiting from the use of the collection policy of the subject gateways to pick better quality web pages to select out of the general web crawled. The new system allowed focusing on the particular subject areas of the subject gateways rather than a more general web search engine.
This combined system made the precision of the search results better, increased the scope of the number of resources that are covered, leveraged the experience in cataloguing from the subject gateways, is a practical system and is being deployed. It is potentially a highly attractive way of making more use of the substantial investment which the commuity has made in the creation of high quality records in subject gateways.
See also the WSE project home page and the RDN-WSE project home page.
This paper was written describing work done as part of the WSE project funded by the Institute for Learning and Research Technology (ILRT), University of Bristol and the RDN-WSE project funded by the Resource Discovery Network (RDN)[17]. The WSE project was devised and set up by Nicky Ferguson The project was designed and implemented by Dave Beckett. Thanks also to Dan Brickley and Debra Hiom for supporting the WSE work and the others in the Semantic Web group at ILRT.
[1] J. Nielsen, Search and You May Find Alertbox, July 15, 1997, http://www.useit.com/alertbox/9707b.html
[2] DCMI, Dublin Core Metadata Element Set, Version 1.1: Reference Description, http://dublincore.org/documents/1999/07/02/dces/ 2 July 1999.
[3] K.G. Saur, UNIMARC Manual : Bibliographic Format. - 2nd ed., München, London, New Providence, Paris, 1994.
[4] OCLC, Dewey Decimal Classification (DDC), http://www.oclc.org/dewey/
[5] S. Lawrence, C. Lee Giles, Searching the World Wide Web, Science, volume 280 number 5360, pp 98-100, 1998
[6] S. Brin, L Page, The Anatomy of a Large-Scale Hypertextual Web Search Engine, Proceedings of the 7th International World Wide Web Conference, April 1998
[7] J.M. Kleinberg, Authoritative Sources in a Hyperlinked Environment, Proceedings ACM-SIAM Symposium on Discrete Algorithms, Jan 1998. Also available as IBM Research Report, No. RJ 10076, May 1997.
[8] L. Page, S. Brin, R. Motwani, T. Winograd, The PageRank Citation Ranking: Bringing Order to the Web, 1998, http://www-db.stanford.edu/~backrub/pageranksub.ps
[9] S. DeRose, E. Maler, D. Orchard, XML Linking Language (XLink) Version 1.0, W3C Recommendation, 27 June 2001, http://www.w3.org/TR/xlink/
[10] D. Brickley, J. Kirriemuir, J. Tredgold, et al., Prototype Integrated SBIG/Index interface, DESIRE project WP3.5, Dec 2000, http://www.sosig.ac.uk/desire/index/integration.html
[11] S. Chakrabarti, M. van den Berg, B. Dom, Focused Crawling: A New Approach to Topic-Specific Web Resource Discovery, Proceedings 8th World Wide Web Conference, May 1999.
[12] O. Lassila, R.R. Swick (eds): Resource Description Framework (RDF) Model and Syntax Specification, W3C Recommendation, 22 February 1999, http://www.w3.org/TR/REC-rdf-syntax
[13] Combine System for Harvesting and Indexing Web Resources, DESIRE and Nordic Web Index Projects, Netlab, Lund University, 1998-2000. http://www.lub.lu.se/combine/
[14] D. Beckett, The Design and Implementation of the Redland RDF Application Framework, Proceedings of 10th International World Wide Web Conference, Hong Kong, May 2001.
[15] R. Dornfest (ed): RSS 1.0 Specification, http://purl.org/rss/1.0/, 19 December 2000
[16] MedCERTAIN - Certification and Rating of Trustworth Health Information, http://www.medcertain.org/
[17] UK Resource Discovery Network (RDN), http://www.rdn.ac.uk/
[18] Open Archives Initiative (OAI), http://www.openarchives.org/