We address the problem of creating dynamic database-backed web applications. We show how the well-known entity-relationship (E-R) modeling technique can be exploited when creating the middle tier in a 3-tier web application. We present the idea of a user-level data model (UDM) for modeling responses to individual requests, and show how to map the UDM to the application's E-R models. With these techniques, the problem of building back ends for web applications reduces to one of creating and editing UDMs. The result is a drastic speedup in application creation time, with typical reductions of 70% or more. In most cases, these techniques allow us to edit the behavior of a running application in almost real time. These ideas are incorporated in zeroCode, a Java-based workbench for creating web middleware.
The Internet is now ubiquitous, and web applications are commonplace. In contrast to the early days of the web, when most content was served from static HTML pages, today's applications are invariably database-backed and serve mostly dynamic content. It is now the norm for web applications to interact with multiple databases, mail servers and other data sources. Consequently, web applications have become much more complex, and are much harder to develop and maintain. This is, of course, the reason for the long development cycles for web applications. Attempts to shorten the development cycle often result in unreliable, inextensible or unmaintainable code because of increased developer stress.
Our approach to solving this problem is based upon a minimalist data model that abstracts away the essential data elements required in a dynamic web page. We call this model the user-level data model (UDM). The UDM accurately captures the data needs of typical web pages, and at the same time incorporates the necessary mappings to the entity-relationship models for the multitude of data repositories (such as relational databases or e-mail servers) manipulated by the application. A key benefit of this idea is a complete separation of the middle tier from the front end, thus allowing multiple renditions of the data from the data model (e.g., via an HTML page, an applet or an XML document). We show efficient algorithms that interpret this data model to perform its operations in the application.
Our tool set includes a web-based UDM editor via which a site designer can rapidly create UDMs and see them in action in almost real time. This enables us to address very complex application needs, in which multiple data sources must be queried and updated in the same transaction, with far less effort than using more traditional means. The tool set is accessible at the zeroCode web site.
In the remainder of this paper, we present the conceptual underpinnings of the user-level data model. We show how to map E-R models into UDMs, and describe algorithms for using UDMs to drive the page-level transactions that are typical in web applications. We also include a brief overview of the web-based UDM design environment that is part of our tool set.
We first present a brief discussion of the entity-relationship model, and subsequently we describe the UDM and the mechanisms for mapping UDM components to E-R models.
The entity-relationship model was originally defined by Chen and developed by many other authors. E-R modeling is a well-understood discipline, so we will not discuss its details here; see, for example, Date for an overview. For our purposes, we will define a restricted version of Chen's modelling structure. With our restrictions, the entity-relationship model structure corresponds closely to the physical models occurring in real-world database schemas. At the same time, however, this restricted version is well suited for dealing with most practical data repositories, even non-relational ones, as we will see subsequently.
An entity defines a type of object, and is simply an aggregate of named
attributes, where each attribute is a primitive data element such as a
number, string or date. We require that all instances of an entity type have
the same set of attributes. This is analogous to the definition of a table in a
relational database, where every record of the table is required to include all
(and only) the columns of the table. For example, we might define an
Employee entity in the context of a relational database as
consisting of the attributes name (a string),
phoneNumber (a string) and dateOfBirth (a date).
Similarly, we can define a Message entity (for a mail
server) as consisting of the attributes senderEmail,
senderName, subject, recipientEmail and
messageBody.
An attribute x of an entity E may be marked as non-null, requiring that every instance of E must include a value for x.
An attribute x of an entity E is distinguished as its key if (a) every instance of E has a value defined for x (i.e., x is non-null), and (b) no two instances of E have the same value for x. Thus the value of an instance's key can be used to uniquely identify the instance. Naturally, an entity can have multiple key attributes, and one of them is usually distinguished as its primary key.
Relational databases usually include support for compound keys, which are sets of attributes that together constitute a unique specification of an instance. For the present, we will ignore compound keys.
A one-to-many relationship from an entity U to an entity V associates an instance of U with zero or more instances of V. For such a relationship to exist, we require that an attribute v of V be designated as referring to a key attribute k of U, i.e., the only permissible values of v in instances of V are those that occur as key values of k in instances of U. In these circumstances, we say that v is a foreign key that refers to k in U.
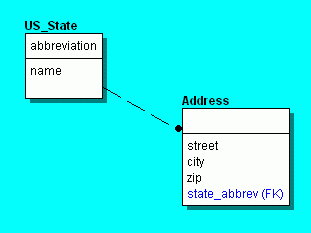
For example, suppose we
have two entities: a US_State entity with attributes
abbreviation and name, with abbreviation
being a key, and an Address entity
with attributes street, city, zip and
state_abbrev. With the restriction that every
state_abbrev value occurs as a value of abbreviation
in some US_State instance, we have a one-to-many relationship from
US_State to Address (See figure.)
In programming-language terms, these definitions mirror the data structures
that one would use when representing such objects in a program. For example,
suppose we need a C program that manipulates addresses and states. We would use
two struct definitions representing the two kinds of data
aggregates, and maintain a pointer from the Address struct to the US_State
struct, thus allowing us to obtain the state associated with a given
address. By comparison, in the E-R model above, we are simply using the
state_abbrev attribute of the Address entity as a pointer value to refer to a
corresponding instance of the US_State entity. This analogy reinforces the idea
that foreign keys in relational schemas serve the same purpose as pointers in
programming languages. The only conceptual difference between a pointer and a
foreign key is that a pointer is usually allowed to contain any memory address
regardless of whether the address is that of a pointed-to object, but in most
relational databases the only legal values allowed for a foreign key are those
that uniquely identify an instance of the pointed-to entity type.
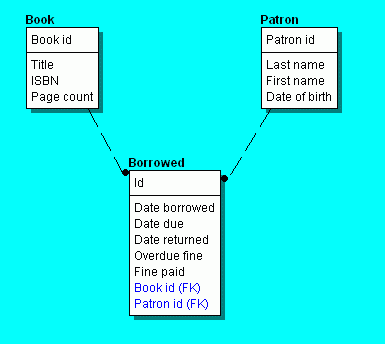
Many-to-many relationships between two entities may be regarded as a
combination of two one-to-many relationships — in fact, they are usually
implemented via an intermediary (linking) entity that encapsulates the
relationship. The figure above
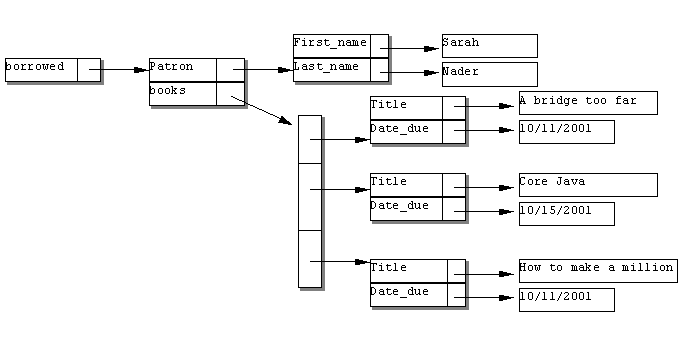
illustrates this idea. This figure shows part of a library's database schema,
with two entities, Book and Patron, linked via an
intermediary Borrowed entity. The linking entity represents two
one-to-many relationships, one from Book to Borrowed and one from Patron to
Borrowed. It also includes attributes specific to the relationship, such as
the date that the book was borrowed by the patron and the date that it is due.
Web applications usually need to deal with multiple providers of data —
databases, mail servers, user sessions, file systems, etc. Invariably, each
such data provider can be modeled via an entity-relationship model.
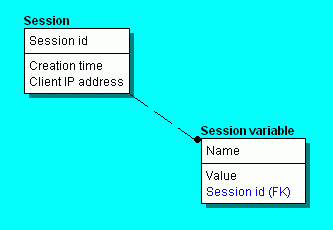
For instance, consider the per-session data that such an application maintains.
It is common for session data to include session variables that are
named data values. We can model the notion
of a session in a web application with two entities: a Session
entity that has attributes corresponding to session id,
creation time and client ip address, and a
Session variable entity that has attributes variable
name, value and session id. The session
id attribute of the Session variable entity defines a
one-to-many relationship from Session to Session
variable. This model accommodates multiple session variables
coresponding to a given session. The figure below
illustrates this idea.
We will use the term data port to refer to the means for accessing such a repository. More precisely, a data port is defined in the context of a particular E-R model, and provides a mechanism for exchanging (i.e., retrieving or storing) data with a repository whose data satisfies that model. For example, we can create a session data port that assumes the data model of the above figure and exchanges data with the current user session. Similarly we can create a mail data port whose 'retrieval' operation involves querying a mail server and retrieving mail messages, and whose 'storage' operation is that of sending e-mail. These examples underscore the point that E-R models are not limited to relational databases, but have far wider applicability.
Every dynamic page includes static and dynamic
parts. The static part is usually the HTML markup, and the dynamic part
consists of strings substituted into the markup. This is, of course, the basis
for the well-known idea of the template. Usually, a template
intersperses markup and static content with "code segments" for producing the
dynamic parts. The latter are usually demarcated with special symbols. For
example, JSP pages use the symbols
<% and %>, while FreeMarker pages use ${ and }. A
template expansion engine performs the necessary code execution and substitutes
data values for the dynamic parts before serving up the page. Templates are now
widely used as the primary means for separating code look-and-feel from data
[Messerschmidt, Geary].
Many template expansion engines, including JSP, allow arbitrary code segments to be placed between these symbols to enable computation of data values. However, it is generally accepted that, in the interests of maintainability and extensibility, the design should adhere to the model-view-controller paradigm [Burbeck] and these segments should include only references to variables but not any code (see, for example, Hunter or Wilson). Such strong separation between code and templates is also advocated by template engines such as WebMacro and Velocity. As we will see presently, our data model includes this separation at its core.
We now describe the central idea of this paper, that of a user-level data model. We will motivate our ideas via a simple problem: Show a web page that accesses the tables of the library example above and displays the attributes of a given patron and the books that he or she has borrowed.
As a first attempt at a solution, we might create a simple HTML template for this purpose. The figure below shows the template, along with sample output that it might produce. The template variable notation used here is that of the FreeMarker package, but our approach is easily modifiable to use other template expansion engines.
<html>
<body>
Patron: ${First_name} ${Last_name}<br>
Borrowed books:<br>
<list books as b>
<i>${b.Title}</i> due on ${b.Date_due}<br>
</list>
</body>
</html>
|
Patron: Sarah Nader Borrowed books: A bridge too far due on 10/11/2001 Core Java due on 10/15/2001 How to make a million due on 10/11/2001 |
Clearly, the only data elements we need to produce for the page are the
patron's first and last name and the list of books he or she has
borrowed. These are obtained via the three template variables
First_name, Last_name and books. The
<list> tag allows iteration over the books
list, with a running variable named b. Each element of this list
as an aggregate with two components, Title and
Date_due.
With this template in place, the server-side logic for displaying this page comprises the following steps executed when a request for the page is received:
Typically, it is step 1 above that is the most programming-intensive and error-prone, since it usually requires personnel with multiple skills: database access (via SQL), programming languages (e.g., Java or Perl) and web technology such as HTTP and other protocols. The problem is compounded for large web applications with several hundred web pages. This is the problem we seek to solve.
Our first step is to impose an organization on the data to be displayed in the page. Instead of thinking of the data elements as three disparate pieces of data, we can think of them as parts of a single unified tree-like representation as in the figure below.
| 1. |
borrowed
| root | ||
| 2. |
Patron
| aggregate | ||
| 3. |
First_name
| attribute | ||
| 4. |
Last_name
| attribute | ||
| 5. |
books
| list of aggregates | ||
| 6. |
Title
| attribute | ||
| 7. |
Date_due
| attribute |
In this picture, we use indentation to denote the parent-child
relationship. So the tree has a root, borrowed, with two children
Patron and books. The Patron node
denotes the aggregate of attributes of the Patron, including the first and last
names. So the two attributes are shown as leaf children of the
Patron node. The books node denotes a list of
aggregates, in which each aggregate contains the attributes Title
and Date_due. Therefore, books also has two leaf
children corresponding to its attributes.
In the application, we can represent this tree
with a simple data structure composed of maps (or hash tables) and lists. The
picture above depicts this data structure containing data corresponding to the
HTML shown earlier. The top-level
element of the data structure is a map with a single key,
borrowed, whose corresponding value is itself a map with two keys,
Patron and books. The Patron key has an
associated value that is also a map with two keys, First_name and
Last_name, with corresponding attribute values. The
books key has a list of maps as its value, and each element of
this list is a map with two keys, Title and
Date_due. We will refer to this data structure as a data
tree. Many template engines, including FreeMarker, can directly produce an expansion of a template
when given the data tree as parameter.
We now see that the structure of the tree, including its node names, attributes and parent-child relationships, is a generic entity, while the data tree is a particular instance of the structure. This distinction is very similar to that between classes and instances in object-oriented languages. The structure can be created and edited separately from the application that uses the structure, just as class descriptions are created and edited routinely by Java developers. This idea is at the heart of this paper.
To use the UDM tree, we must first map its elements to the E-R models it uses. This task is significantly easier if we insist that every non-leaf node of the UDM tree is associated with at most one entity type in the repository, and that the non-leaf node includes one attribute child, a leaf, associated with every attribute of that associated entity. The diagram below depicts such an enhanced version of the simple tree above.
| Node # | Node name | Kind | Entity | Condition |
|---|---|---|---|---|
| 1. |
borrowed
|
root | ||
| 2. |
Patron
|
aggregate | Patron |
Patron.Patron_id = ?id?
|
| 3. |
Patron_id
|
attribute | ||
| 4. |
First_name
|
attribute | ||
| 5. |
Last_name
|
attribute | ||
| 6. |
Date_of_birth
|
attribute | ||
| 7. |
books
|
list of aggregates | Book |
Book.Book_id = Borrowed.Book_id and
Borrowed.Patron_id = ?3?
|
| 8. |
Book_id
|
attribute | ||
| 9. |
Title
|
attribute | ||
| 10. |
ISBN
|
attribute | ||
| 11. |
Page_count
|
attribute | ||
| 12. |
borrowRecord
|
aggregate | Borrowed |
Borrowed.Book_id = ?8? and Borrowed.Patron_id = ?3?
|
| 13. |
Date_borrowed
|
attribute | ||
| 14. |
Date_due
|
attribute | ||
| 15. |
Date_returned
|
attribute | ||
| 16. |
Overdue_fine
|
attribute | ||
| 17. |
Fine_paid
|
attribute | ||
| 18. |
Book_id
|
attribute | ||
| 19. |
Patron_id
|
attribute |
With the requirement that each non-leaf node must be associated with one
entity, we now need two separate non-leaf nodes to extract the book's title and
its due date, because these two attributes are drawn from different
entities, Book and Borrowed respectively. This is
why we need a separate non-leaf node borrowRecord
corresponding to the Borrowed entity. Moreover, we make the
borrowRecord node a child of the books list node
because we want each instance of borrowRecord to be associated
with the corresponding instance in the list of books.
We can now provide a more precise definition of the UDM tree. A UDM tree is a tree with the following properties:
We will also annotate each UDM node with additional properties, such as
the conditions associated with retrieving its data. The
diagram above
depicts the retrieval conditions as SQL where clauses, since that is
the "condition" which makes sense in the context of a relational
database. In this diagram, the notation ?id? (in the
Patron node's condition) represents the id of the Patron whose
records must be retrieved, and the notation ?3? represents the
value of node number 3 (the Patron_id node). Note that although
this diagram shows SQL, in the general case the condition associated with a
UDM tree node is not limited to being an SQL structure — it can be an
arbitrary string that encodes the selection criteria applied by the node's data
repository.
It is straightforward to create a descriptor, e.g., in XML format, that encapsulates all the information in this enhanced version of the UDM tree. (For brevity, we will omit the details of this descriptor construction.) Such a descriptor gives us a key benefit. We can write a generic traversal algorithm that takes as input such a descriptor (and any necessary parameters, e.g., the patron id), traverses the tree and produces the corresponding data tree. This data tree can then be fed to the template expansion engine to obtain the finished product to serve to the browser. (We will refer to this traversal algorithm as the UDM retriever — this algorithm is described subsequently.) The existence of the descriptor now enables us to separate design-time from run time: at design time, we engage in creating and editing the UDM structure descriptor, while the run-time engine uses the descriptor to carry out data transfers and business logic.
With this background, we can reformulate the original page display problem — that of displaying a patron's books — in three steps:
First_name is replaced with
borrowed.Patron.First_name.
<html>
<body>
Patron: ${borrowed.Patron.First_name} ${borrowed.Patron.Last_name}<br>
Borrowed books:<br>
<list borrowed.books as b>
<i>${b.Title}</i> due on ${b.borrowedRecord.Date_due}<br>
</list>
</body>
</html>
|
Now we will consider the data retrieval problem: Given a UDM tree and any necessary parameters, we must retrieve the data elements specified by the UDM tree and construct the corresponding data tree. In this paper, we will restrict ourselves to UDM trees that use just one data repository. Extending this framework to handle multiple repositories is not hard.
The obvious approach to retrieving UDM data is to traverse the tree recursively, retrieving the appropriate data during traversal. Here is a simplified formulation of this traversal, in Java-like pseudo-code. This formulation omits low-level details and optimizations.
Map buildDataTree (UdmTree tree, Map parameterMap) {
Map dataTree = new HashMap();
return traverse (tree.root(), parameterMap, dataTree);
}
Map traverse (UdmTreeNode v, Map parameterMap, Map dataTree) {
for (each child w of v) {
if (w is an aggregate node) {
Map dataRecord = getDataRecord (w, parameterMap, dataTree);
dataTree.put (w.name(), dataTree);
traverse (w, parameterMap, dataTree); // Recurse
} else if (w corresponds to a list of aggregates) {
List dataList = getDataList (w, parameterMap, dataTree);
dataTree.put (w.name(), dataList);
Iterator itr = dataList.iterator();
while (itr.hasNext()) {
Map dataRecord = (Map) itr.next();
traverse (w, parameterMap, dataTree);
}
}
}
}
The buildDataTree method returns the data tree defined by the
given UDM tree, in the context of the given parameters. The data structure it
returns is a Map, which in turn may contain other maps or lists according to
the data tree structure described
earlier. The method's second parameter, parameterMap, contains
keys that are parameter names, with corresponding values. For instance, in the
library example above, this map would include a key named id
needed to specify the patron whose data must be retrieved. The
buildDataTree method simply forwards its call to the recursive
traverse method, which does most of the actual work.
The traverse method visits each non-leaf node of the UDM tree
and retrieves the data specified by the node. It uses the two methods
getDataRecord and getDataList (whose implementations
are temporarily omitted) for the actual data retrieval, retrieving single- and
multi-valued data, respectively. The getDataRecord method embodies
the logic for retrieving a single record, whose type is its parameter node's
entity type, from the node's repository, according to the node's retrieval
condition. The getDataList method is similar, except that it
returns a List of the data records that match the node's condition.
Both the methods getDataRecord and
getDataList are given as parameter a reference to the
partially-formed data tree (the last parameter to each method). This is
necessary because the retrieval condition at a given node can depend upon
the results returned by previously-retrieved nodes. For example, the
condition in the above UDM
for the books node depends on the value of the node number 3,
the Patron_id node, which will have been retrieved earlier in
the traversal. Therefore, when the data for the books node is
to be retrieved, the node's data port (invoked from the
getDataList method) expands the condition into an appropriate
where clause by replacing the occurrence of ?3? with the
corresponding value in the partial data tree. This mechanism enables us to
set up dependencies between tree nodes as dictated by the needs of the web page
to be rendered. We refer to this situation as a retrieval
dependency: Specifically, the books node is said to have a
retrieval dependency on the Patron_id node because the latter's
value must be available before the former can be retrieved.
Note also that the above retrieval algorithm is rather simplistic, in that in the interests of brevity it omits optimizations that are important in practice. Also, it depicts the algorithm as a simple pre-order traversal, and that is often not adequate in practice. This is because UDMs may include complex retrieval dependencies that cannot be satisfied in a pre-order traversal (e.g., when a node has a retrieval dependency on another node further down in the tree). It is not difficult, however, to extend this algorithm to incorporate a topological sort of its nodes, so that arbitrary retrieval dependencies can be accommodated. This enables us to retain the purely declarative aspect of the UDM tree.
Next, we will examine how the UDM tree can be used to direct the storage of data into a repository. The idea here is to use the UDM to drive data storage the same way it is used for retrieval. In this case, data is transmitted from user to repository instead of the other way around. The user provides data by submitting an HTML form, and the server must use that data to update the appropriate data entities in the repository.
There are at least two problems that make the storage process more interesting (and, of course, more complicated) than the retrieval process. The first is what we call the tree reconstruction problem: When the user submits a form, the form data appears to the server as an amorphous collection of key-value pairs, and we must resurrect a complete data tree structure from this collection. The second problem is the storage dependency problem, which we will discuss presently.
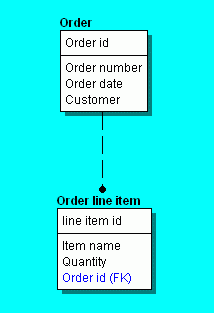
First we will consider the tree reconstruction problem in the context of the following example. Suppose we wish to create an "order entry" page that allows the user to add a new order into a database. For this example, an order consists of "header" information such as the date and the customer placing the order, and several "line items" listing the the items being ordered. The figure below illustrates what the page might look like, and the corresponding tables and their relationship.
Here, the web form's submission must cause insertion of one record into the Order table and multiple records into the Order_line_item table. In general, the number of records to be inserted into the Order_line_item table is not fixed, because the designer could allow a variable number of line items, e.g., via JavaScript code in the HTML page. Consequently, the UDM that models this page must be constructed with an aggregate node corresponding to the Order table and a list node corresponding to the Order_line_item table, as shown below.
| Node # | Node name | Kind | Entity |
|---|---|---|---|
addOrder
|
|||
order
|
aggregate | Order | |
order_id
|
attribute (primary key) | ||
order_number
|
attribute | ||
order_date
|
attribute | ||
customer
|
attribute | ||
items
|
list | Order_line_item | |
line_item_id
|
attribute (primary key) | ||
item_name
|
attribute | ||
quantity
|
attribute | ||
order_id
|
attribute (foreign key) |
When the form is submitted, its contents appear to the server as a collection of key-value pairs, with each key being the name of a form element, with the content of the form element as the corresponding value. For example, if the order number field is represented via an HTML tag such as
<input name="order_no" type="text">then the server receives a corresponding key-value pair like this:
order_no=011101
The server must now construct a data tree from this collection of pairs. But there are multiple occurrences of the attributes of the Order_line_item table, so the server cannot identify the instance to which a particular attribute belongs.
The problem is complicated by the fact that the UDM tree can include list nodes, and these lists can be nested to arbitrary depths. i.e., we can have lists of lists of lists. For each leaf that is nested in a list, we have to identify the instance number in the list in which the leaf belongs. Therefore we cannot use a simple one-to-one correspondence between UDM tree leaf names and form element names.
Our solution to this problem uses encoded tag names for the form
elements. For a UDM tree leaf v, the tag name(s) for the form element(s)
associated with v encodes the node numbers of the nodes along the path
from root to v in the UDM tree, along with instance numbers of any list
nodes along this path. For example, refering to the HTML page above, the form
element for the order number is assigned the tag name 0-1-3, since
there are no list nodes along the path to the order number node. The two
quantity form elements are assigned the tag names
0-6:0-9 and 0-6:1-9, accounting for the list node
number 6 along the path to the quantity node in the UDM.
In general, given a leaf v in a UDM tree, the tag name for v's form elements has the structure x0-x1-...-xt, where xi is either
With this encoding scheme in place, it is a straighforward exercise to write an algorithm that, when given a parameter packet of key-value pairs submitted from a form, recursively traverses the UDM tree and reconstructs the data tree.
Note that the encoding suggested above is somewhat redundant, in that the tag names do not need to include the node numbers of all the nodes along the path: we could omit the node numbers of all non-list nodes on this path, retaining just the leaf node and the list nodes and corresponding instance numbers. This is because each UDM tree node is given a distinct node number, as noted earlier. However, our convention simplifies the algorithms involved, and is not much more expensive in either time or space.
Having resolved the issue of how to reconstruct the data tree, we can now address the question of how to insert the data records into the repository: given a data tree and an associated UDM tree, the problem is to insert the data records in the data tree into corresponding tables in the database. At first blush, the solution seems obvious: simply traverse the data tree from root to leaf, inserting the data records into the repository along the way. This solution does not perform correctly, however, and one reason is that it does not properly account for dependencies between nodes.
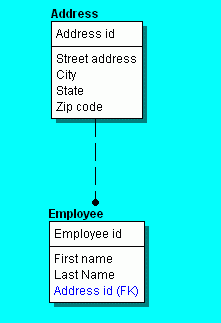
To illustrate the difficulty with a simple traversal, consider another example where a web page is used to add an employee and corresponding address into a database. The figure below illustrates this page, along with the two tables into which records are to be added. The table relationship is set up so that a given address can have multiple associated employees, which is not an unusual situation in practice.
Consider a UDM tree that models this page. Since it must add records
into two separate entities (tables), it will include two corresponding
non-leaf nodes, as required by the definition of a
UDM tree. The example tree is shown below. Note that there are numerous
other ways to build a UDM tree for the same web page; for example, we could
have chosen the address node to be a sibling of the
employee node, instead of making it a child. We cannot impose
limitations on the way the UDM tree is built, so we must account for all
possible trees. We have chosen
this particular structure to illustrate some difficulties that arise.
| Node # | Node name | Entity | Storage binding |
|---|---|---|---|
addEmployee | |||
employee
|
Employee | ||
Employee_id
| |||
First_name
| |||
Last_name
| |||
Address_id
|
#7 (addEmployee.address.Address_id) | ||
address
|
Address | ||
Address_id
| |||
Street_address
| |||
City
| |||
State
| |||
Zip_code
|
It is apparent from the tree structure that a top-down pre-order algorithm
for record insertion will fail in this case. This is because the pre-order
algorithm will attempt to first insert the Employee record and then insert the
Address record. However, the Address record
must be inserted before the Employee record can be inserted, otherwise we would
not preserve referential integrity in the database. Moreover, when a record is
added to the Employee table, we would want the Address_id foreign
key of the newly-added Employee record to be the primary key of the record
added into the Address table. To accomplish this, we mark the
employee node's Address_id attribute (i.e., node #5)
as having a storage binding to the primary key attribute of the
address node (i.e., node #7), as shown in the figure above. This
situation causes a storage dependency of node #5 on node #7. Note that
there is an implied storage dependency of node #1 (the employee node) on node
#6 (the address node).
Storage dependencies are similar to retrieval dependencies, in that if a node v has a storage dependency on another node w, then v's content can be added into its repository only after w's is added. But, as in this example, the storage dependency occurs from a node to another node that is farther down in the tree. This means that we cannot use a simple pre-order traversal to add records into the repository, because if we did, we could violate dependencies: in the example above, the pre-order traversal would attempt to add a record into the Employee table before adding the corresponding record into the address table. Storage dependencies such as the one in this example are quite common, and therefore must be handled by the UDM storage algorithm.
To solve this problem, we employ a multi-pass approach. Each pass performs a recursive traversal of the UDM tree, and adds those records that do not violate storage dependencies during that pass. Here is the algorithm, in Java-like pseudo-code.
insert (Map dataTree, UdmTree udmTree) {
Mark all non-attribute nodes of udmTree as "unprocessed";
while (there are unprocessed nodes) {
doOnePass (dataTree, udmTree.root());
}
}
doOnePass (Object dataTree, UdmTreeNode v) {
Let S be the set of nodes on which v has storage dependencies;
if (v is an aggregate node) {
Map dataTreeMap = (Map) dataTree;
Map dataRecord = (Map) dataTreeMap.get (v.name());
if (every node in S has been processed) {
putDataRecord (v, dataRecord);
mark v as "processed";
}
for (each non-attribute child w of v) {
Object childTree = dataRecord.get (w.name());
doOnePass (childTree, w); // Recursive call
}
} else if (v is a list node) {
List dataList = (List) dataTree.get (v.name());
for (int i = 0, n = dataList.size(); i < n; i++) {
Map record = (Map) dataList.get (i);
if (every node in S has been processed) {
putDataRecord (v, record);
mark v as "processed";
}
for (each non-attribute child w of v) {
Object childTree = record.get (w.name());
doOnePass (childTree, w); // Recursive call
}
}
} else {
// In this case v is a leaf, so we don't do anything.
}
}
The insert method is given as parameters a data tree
(represented by the top-level map parameter, dataTree) and the
corresponding UDM tree. This data tree is constructed using the tree
reconstruction process outlined earlier.
The doOnePass method performs a single recursive traversal of
the UDM tree while simultaneously traversing the data tree. During the
traversal, it invokes the putDataRecord method (whose body is
omitted for brevity), which performs the insertion or update of a single
record. The doOnePass method also updates the status of the nodes
from 'unprocessed' to 'processed' and ensures that an insertion is carried out
at a node only if all the nodes on which it depends have been processed, so all
its dependencies are satisfied.
Note the key benefit that arises from the use of this algorithm. The designer of the UDM need not track the order in which she creates UDM nodes. She is free to create them in any order, and the system adjusts itself to perform data insertions in the correct order. We have found this feature to be very valuable in practice. By contrast, a traditional programming approach would involve the tedious and error-prone way of manually keeping track of foreign key dependencies, to ensure that records are inserted in the correct order.
It is not very hard to construct a formal proof that this algorithm
correctly handles all storage dependencies. The proof is omitted for brevity. A
natural, related question to ask is: How efficient is this algorithm? Clearly,
each time insert invokes doOnePass, the latter looks
through all the data elements in the data tree once, so it expends time linear
in the size of the input data. Thus its worst-case behavior is governed by the
number of passes it makes, i.e., the number of executions of the loop in the
insert method. Since the doOnePass method performs
pre-order traversal, any storage dependencies that go upward in the UDM tree
— from descendant to ancestor — are handled in one pass, because
the ancestor is processed before the descendant is processed. But downward
dependencies need a separate pass. A moment's reflection should convince that
the number of passes cannot exceed the length of the longest downward
dependency chain plus one.
This suggests a modification to the algorithm, to perform a post-order insertion, where necessary, in addition to the pre-order insertion. This modification is easy to implement, and cuts the maximum number of passes in half.
In practice, multiple downward dependencies occur very rarely, and then only in highly pathological situations, because they are counter-intuitive to most UDM design engineers. The modified algorithm processes most UDMs in one pass, and it is very rare to find UDMs that need more than three passes.
The algorithms described above enable us to retrieve and store data via arbitrary UDMs. We can now view the process of constructing a web application in two phases: a design phase and a run-time phase. During the design phase, we determine the web pages to be displayed by the application and identify the flow through them via the appropriate links. We then prepare the necessary UDMs and HTML (or other) templates to display each page. In the run-time phase, the application fields web requests and executes the UDM retrieval and storage algorithms described above. Thus the primary activity in application development shifts from one of coding, testing and debugging to one of designing UDMs and constructing associated HTML templates, a much easier task in practice.
Our tool set includes a web-based UDM editor for incrementally creating and editing UDMs. The UDM editor allows the designer to perform all the functions that one would expect: creating a new UDM, adding and removing nodes to an existing UDM, and moving nodes around in the UDM tree. The UDM editor relies heavily on the E-R models for the data repositories (equivalently, the database schemas) used by the application being built.
An important aspect of UDM editing is the creation of SQL queries associated
with the UDM nodes. This corresponds to the "condition" properties alluded to
in earlier diagrams, e.g., the library example. When the designer adds a new node w as
a child of a parent node v in a UDM, she usually wishes to impose
conditions on w's data retrieval, based on the values in v's
elements. For instance, refering again to the library example, we would want the borrowRecord
record to correspond to the instance of the books node, and we
therefore impose join and selection conditions on the borrowRecord
node.
The UDM editor assists in this process in two ways. First, it lists all available attributes of the table, and allows the designer to choose restriction criteria based on one or more of them. The lists of table and column properties are obtained from the E-R models for the application. Second, and more important, it offers up all the possible paths between the table associated with the parent node v and the one associated with the child w being added. Each such path corresponds to a possible join chain relating the two tables. The designer can simply choose the appropriate join chain without having to code it by hand. These two features make it possible to construct complex SQL conditions without having to hand-code them.
The computation of all possible join chains is accomplished by examining the database schema as a graph and executing a path construction algorithm based on depth-first search [Tarjan]. The details are omitted from the present paper.
A second aspect of the UDM editor is the ability to construct a "starter" HTML template from a UDM automatically. This idea stems from the observation that, in many cases, it is possible to emit an HTML template using a simple traversal of the UDM tree. In very broad terms, the algorithm traverses the UDM tree in pre-order, emitting HTML grouping markup (such as table tags) when it encounters a non-leaf node, and variable references or form elements when it encounters leaf nodes.
This "starter" template offers several benefits:
In this paper, we have presented a new data model, called a user-level data model (UDM), for representing data manipulated by web applications. The UDM is an organizational device for representing a packet of data elements, and is well suited for modeling data not merely for web applications but in any scenario where a request-response paradigm is used. Since the UDM does not contain any rendition information, it can be used in a wide range of renditions, from HTML or WML templates and Java applets for end users to XML documents for business-to-business data interchange.
We have also presented a brief overview of our design environment for creating and editing UDMs. Many of the more appealing features of this environment, such as foreign key dereferencing, relators and filters, have been omitted due to space constraints. For the same reason, we have omitted details about data ports for allowing application interation with non-database data providers such as mail servers, and consequently many of the examples in this paper have been limited to relational databases. More details about the design environment are available online at www.zerocode.com.
UDM trees bear some resemblance to the schema tree structure proposed by Finkel and Herrin. These authors, however, applied their structure very differently. They proposed the model as being conceptually closer to the way programs retrieve data, and investigated how to implement the model directly as a storage mechanism. Our approach, by contrast, is to simply apply the model to support existing relational databases and then generalize to other repository types.