Standards for describing Learning Objects (LO) are gaining increasing importance as exemplified by the work of several organizations most notably the IEEE and the IMS Global Learning Consortium, one such standard is the IMS/IEEE Learning Objects Metadata (LOM) standard[1].Ā These efforts continue to advance the goals of interoperability, but do not address the need for accessibility to the internal composition of the Learning Objects. Under the present standards the LO remains an opaque entity from which valuable information cannot be easily gleaned or harvested, nor introduced or adapted. Neither the need for introducing adaptive features to the LO, nor the need for learner modeling are well addressed.
This paper proposes an approach to the design of Open LO (OLO), which is based on Open standards, mostly XML markup languages and related tools. It exposes an interface to export the results of LO-to-Learner interaction and for LO adaptation. We call InnerMetadata to the collection of layered meta-data mechanisms that are used to describe the OLOs, their adaptive features, and the learner interaction tracing.Ā LO objects designed according to this architecture still retain the encapsulation and modularity required to abstract those implementation aspects of a LO that an author would like to reserve for future enhancement and growth, yet they provide a systematic and consistent interface for extracting the results of the interaction with the learner and for LO adaptation.
The nature of the adaptations that OLO proposes are centered on the learner, and allow the LO to adapt to the evolving model of the learner [2,3,4,5] in terms of language, skill levels, and learning styles. In addition OLOs purport to make accessible the tracing of Learner-to-LO interactions that includes such aspects as: assessment results, LO navigation choices, general capture and time-stamping of learner interaction event, and the interruption and re-start of LO in various states of completion.Ā
Keywords: learning objects, learner modeling, learning object adaptations, learning object standards,ĀXML applications
Learning Object standardization has been receiving increased attention from the IEEE, the IMS Global Learning Consortium, and others. This has included the creation of the Learning Object Metadata[1] (LOM) standard by the IEEE/IMS and others by IMS, such as: the Question and Test Interoperability (QTI) [7], the Learner Information Packaging (LIP)[8], and the LO Packaging [9] standards.
Of these, the LOM standard[1]Ā is purported to describe a LO from a mostly external viewpoint, and includes such elements as: General, Rights, LifeCycle, Technical, Educational, Relations, Classification, Annotations, and Metametadata.Ā The scope of this standard is limited on its internal views of the LO, which remains an opaque entity. Other researchers [10] have also made similar observations. In practice, however, LO are increasingly dynamic, interactive and intelligent entities, and users in different roles require varying levels of access to these internal views.
We believe that extensions to the existing standards could include specifying the creation of a learner-specific trace of LO interactions that correlates a set of control mechanisms on the OLO-learner interface with the learner’s activity.Ā Metadata could also accommodate dimensions of adaptability of the LO itself.Ā
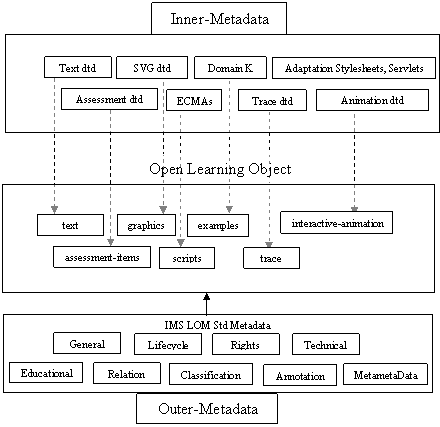
This paper describes our on-going development of Open Learning Objects (OLO) that are data-driven and based on XML markup.Ā OLOs are one component of the Integrated Distributed Environment for eLearning IDEAL [11].Ā OLOs exemplify an open and extensible framework as a set of standard DTDs, tools and generic Agents. The set of DTDs constitute what we call the OLO Inner-Metadata. The Inner-Metadata structures describe a multimedia rich interactive LO that is adapted at the client and server sides.
The OLO architecture exposes these adaptation mechanisms as a layered architecture. Tools that support the creation of OLO are thus easier to develop and use by allowing data-driven generation and updates instead of a tight dependence on programmatic mechanisms.
The OLO architecture is implemented as interactive structured multimedia (see Figure 1). The open use of Inner-Metadata, describing the inner structure of the LO, allows the deployment of LOs using a small set of generic software Agents, the capture of the resulting interaction with the Learner, and the authoring, integration, and adaptation of LOs using standard tools and technologies.
Operationally, OLOs rely on a web-centered client-server model where computational costs are shared by both server and clients [12] . The client-side is implemented using Javascript, with XML documents describing interaction and animation specifications, SVG graphics, and the corresponding plug-ins. The server-side generic Agents are implemented using Java servlets and are driven by XML mark-up that allow them to perform inter-LO navigation, content adaptation ,and learner interaction support and modeling. A persistent back-end native XML database with secure access-controls stores Learner Interaction Trace results within the LIP-based Learner model.Ā A Learning Object Virtual Exchange repository (LOVE [13] ) stores and makes publicly accessible LOs and their metadata descriptions.
Besides relying on IEEE and IMS standards such as LOM, QTI, and LIP; OLOs incorporate Inner-Metadata DTDs for markup that can be easily used by authoring and delivery tools.
OLO’s are organized for authoring and delivery as a layered architecture. Each layer features a similar generic structure as shown in Figure 2 .

In our current research efforts we are experimenting with OLO’s having the following specific layers: Conceptual Layer, Graphic/Iconic/Speech Layer, Animation/sequencing Layer, Interaction Layer, Integration Layer. Higher order layers are implemented through Intelligent Agents technology. This paper will be limited to describing how we are using the first five(5) layers as shown in Table 1.
|
OLO Layers Description |
|||
|
Layer Name |
Content Sub-Layer
|
Inner-Metadata Sub-Layer |
|
|
Content metadata |
Adaptation metadata |
||
|
Conceptual |
LO Knowledge Domain Concepts, Definitions Explanations, Examples, Assessments |
Pedagogic concepts Ontology expressed in OLOtext.dtdĀ markup language |
Language,Prior knowledge,Learning style and skill level authoring hints |
|
Representation |
Alternate representations for Concept layer, usingĀ graphic metaphors, shapes, icons, speech markup |
Shapes, icons, clips or synthesized speech, expressed in SVG graphics, and speech markup language |
Accessibility adaptations, color, contrast, size, fonts. text-to-speech. |
|
Animation and Sequencing |
Synchronization between Conceptual layer and Representation layers. Sequence of states and branch-actions that animate representation. |
Sequence of states representing a learner-meaningful configuration of the Conceptual and Representation layers, line-of-reasoning grouping of states, default and optional line of reasoning, backtracking capability |
Cognitive load, transition grain in terms of number of primitive states, re-ordering of line-of-reasoning state groups, per skill & learning style preferences, default and optional sequences |
|
Interaction |
Defines semantic events that drive animation. |
Semantic-event handlers, Event to shape associations, Capture of Interaction trace |
Selective enabling of event handlers per skill level & learning style, semantic density, cognitive load, speed of interaction |
|
Integration |
Defines component parts to make-up the OLO |
Use the InnerMetadata DTD describing components |
Match Browser (User Agent) and FacilitatorAgent |
Table 1 OLO Layers
A key requisite for intelligent adaptation is learner modeling [2, 3, 4, 5]. Although general learner modeling is considered by many an intractable problem [14],Ā OLOs exploit objective knowledge about the learner’s previous knowledge, skill level performance, learning style, and language. These dimensions can be seen as operating on two different time scales: long term and short term modeling.
Short term modeling measurements includes: number of times a learner reviews the OLO object, total time taken to complete the OLO, a detailed trace of all learner generated events, and the state transitions resulting from those events.
Short-term skill-level modeling is carried out by explicit administration of a formative assessment that uses a set of four (4) categories of questions that are associated with the learner performance on the current OLO topic.Ā The server-side LearnerAgent uses a Āsimplified Bayesian belief network algorithm to map this evidence into a set of five (5) skill levels as defined in the IDEAL [11,13,15,16,17] architecture:
Long-term modeling, attempts to model those aspects of the Learner that we do not expect to change during the course of the interaction with a single OLO. This includes the administration of an Index of Learning Styles (ILS) [18] and of Summative Assessments after completing a group of OLO objects that represent a Unit, a Course, or higher level curricular grouping.Ā
The client-side FacilitatorAgent makes short and long term modeling data available to the server-side CourseAgent. The CourseAgent communicates with a LearnerAgent which stores this information as part of the Learner Information Package(LIP) record [8].Ā The LearnerAgent maps most of this information into a LIP record using the services of a Learner Information System which provides secure access to the records.
ĀTable 2 shows the mapping between the outcomes from the major LO delivery process stages, and portions of the IMS Learner Information Packaging Specification (LIP)[8] record.
LO adaptation is a critical requirement in order to accommodate the large variety of learners that will be accessing the OLO through web-based eLearning Systems.Ā Adaptation is organized at two levels. First, there is inter-LO or navigational adaptation, and second, we have intra-LO or content adaptation.
Content adaptation seeks to use the traits being modeled for the learner to select relevant features or dimensions already built into the OLO throughout its adaptation layers. Ideally we would like to introduce LO adaptations for the largest possible set of learner traits, but we are constrained by the technologies and architecture we adopt, and ultimately by what the computer-based media can afford. Traits such as kinesthetic or haptic feedback preferences fall outside the reach of web-based eLearning.
|
IDEAL Terminology for OLOs LIP Record Major Delivery Process Stage Outcomes |
Learner Information Package Element Names and Cardinality |
IMS LIP XML Binding Specifications V1.0 section number [8] |
|
Learner Record created |
learnerinformation structure is created |
3.1 |
|
Learner Record access rights |
This structure is part of the contentype Āmetadata structure and is included on every atomic element in the record to provide element-level access rights, time-stamp,etc |
3.1.2 and 3.13.2 |
|
Learner Identification |
identification |
3.1.3 and 3.2 |
|
Learner Password/PIN,Username, Certificates, etc. |
securitykey |
3.1.12 andĀ 3.11 |
|
Learner enrolled into a specific curricula at the IDEAL system |
A new goalstructure is added to the record |
3.1.4 and 3.3 |
|
Learner completion of a course |
A new qcl structure is added to the record (qualifications, certifications and licenses) |
3.1.5Ā and 3.4 |
|
Learner enrolled into a specific IDEAL course |
A new course-activity structure is added to the record as a first-level activity |
3.1.6 and 3.5 |
|
Learning Object or Topic is started |
A second-level LO-activity structure is added within the course activity structure |
Note that activity structures are prefixed with a name corresponding to the nesting level. |
|
Learner Interaction Trace is captured |
A third-level trace-activity structure is added within the (second-level) LO/Topic activity structure |
(same) |
|
Learning Object Assessment is initiated |
A third-level assessment-activity structure is added within the (second-level) LO/Topic activity structure. Our meaning of Assessment, Section and Item are as perĀ IMS-QTI |
3.5 Each activity structure created at any nesting level should be identified with the learning object ID. |
|
Assessment Section is initiated |
A fourth-level section-activity structure is added within the (third-level) Assessment activity structure |
3.5 Results of assessment sections, and items, are represented as nested activities. |
|
Section Item is completed |
A fifth-level Āitem- evaluation structure is added within the (fourth-level) Assessment Section activity structure. Each new Item adds one more evaluation structure. |
3.5.13 |
|
A result structure is added to the evaluation |
3.5.13.14 |
|
|
An interpretscore structure is added within the result with a fieldtype of “skillLevel” and a fielddata chosen among (beginner | novice | intermediate | advanced | expert ) |
3.5.13.15 |
|
|
A score structure is added within the result with a fieldtype of “boolen” and a fielddata chosen among (correct | incorrect) |
3.5.13.16 |
|
|
Section Item duration |
A new duration structure is added within the evaluation |
3.5.13.13 |
|
Learning/Cognitive Style Inventory Assessment is administered |
A new ILS-activity element is added to the record as a top-level activity element, follows sameĀ nesting pattern as assessment-activity shown above. |
3.5 |
|
Cognitive style, language, and other pedagogically meaningfulĀ preferences. |
The summary ILS results will be represented in 3.8 Accessibility element within the record.Ā A preference structure is added to the accessibility element for each cognitive style preference identified by the ILS. |
3.1.9 and 3.8, 3.8.4 |
Besides language and accessibility, we are researching mechanisms for adaptation that can be correlated with two major sets of learner traits: skill levels and learning styles. We view these as relatively independent sets of traits, where skill level is a short-term frequently updated trait measured on a per-LO basis, while learning style is long-term and updated mostly under learner control.ĀĀ Table 3 shows correlations between these learner traits and some of the adaptations that can be designed into learning objects with our current OLO architecture.
|
OLO Adaptations vs. Learner traits |
||
|
Language (lang), Learning style(style), Skill level (skill), Accessibility (access) |
||
|
Adaptive feature |
Learner Trait |
|
|
Language of LO text |
lang |
|
|
Depth of treatment of a concept |
skill |
|
|
Inclusion of optional/enrichment material |
skill, style |
|
|
Number of LO state changes per unit-time |
skill |
|
|
Size or information content granularity of LO states |
skill |
|
|
Semantic-density or difficulty granularity of LO states |
skill |
|
|
Self-pacing on inter-LO navigation |
skill |
|
|
Self-selection on inter-LO navigation |
skill |
|
|
Self-pacing on intra-LO navigation |
skill |
|
|
Self-selection on intra-LO navigation |
skill |
|
|
Ordering of line-of-reasoning clusters within an OLO |
style |
|
|
Ordering of examples, general rules, summary concepts |
style |
|
|
Selection of visual metaphors and icons |
style |
|
|
Text to speech conversion selection |
style, access |
|
|
Adjustments in colors, fonts, and size |
style, access |
|
|
others |
style, skill |
|
There is no consensus in the educational community about what constitutes skill levels and learning styles, but there is abundant literature that confirms their relevance. We hope to use the IDEAL eLearning environment as a platform to test and explore these and similar issues from a unique perspective; that of a potentially very large learner pool as available through the web. Such a goal requires the adoption of a LO framework that is open and extensible.ĀĀ
Although adaptability is a worthy goal, we have identified at least three (3) major issues that constitute obstacles to a self-contained, yet adaptable, OLO. Many of these issues have been addressed under different guise by Software Engineering (i.e., Pattern Languages) as they have to do with the management of complexity, decoupling of interactions to facilitate adaptation in LOs, and the localization of control for changes and adaptations.Ā
First, domain knowledge representation in an adaptation-independent way, though highly desirable, may be hard to achieve. The capture of domain knowledge following some pedagogic ontology and its markup should be orthogonal to the markup for adaptation purposes.Ā The best situation is one where the adaptation markup can be layered on top of the domain knowledge markup without any undesirable interactions.Ā This facilitates a layering or separation of concerns that helps scalability. The OLO’s Conceptual layer is an attempt at achieving this independence, while allowing for the introduction of adaptation markup at this level mostly as hints for the authoring of subsequent layers. Our current implementation uses a brief ontology of pedagogic concepts designed to closely fit our prototype knowledge domain consisting of a Data Structures course. A review of the literature however shows the possibility for more elaborated ontologies, as for example that by Leidig [31].Ā We use empty but attributed elements enclosed within content elements as mark-up for the adaptation sub-layer.
Second is the orthogonality or relative independence between different adaptation dimensions.Ā It is conceivable that adaptation attempts might lead to contradictory or incompatible changes to the OLO. For example, an adaptation that manages the animation sequence step size according to the need to adapt to semantic density or short term memory learner characteristics, can run into conflict with an adaptation need for speech output, since the speech can not be easily sped-up to accommodate the higher information rate.Ā This undesirable coupling should be avoided whenever possible or resolved with the help of the learner model or following some heuristic. OLO’s layered architecture promotes adaptation orthogonality by allowing the localization and separate capture of adaptations in particular layers.
Third, the sheer size of the task of authoring LO along such a wide variety of adaptation dimensions presents a problem. The scalability of authoring LOs is questionable when the efforts from several authors in different roles can not be easily integrated, coordinated and combined. This tends to be the case with proprietary architectures that limit the pool of potential authors or require co-location.Ā For OLOs we have adopted an architecture with a set of highly de-coupled layers and a data-driven approach that allows independent authoring using standard XML tools. This increases the pool of potential authors making collaboration and shared authoring possible by lowering the complexity to individual collaborators, and making the authoring task increasingly tractable and scalable. For example the language adaptation (i.e. translation) can easily proceed just slightly behind the main Conceptual layer authoring task. Also once the basic Conceptual layer has been authored it is possible to work on the Representation layer authoring the speech and the graphics layers in parallel. Once Conceptual and Representation layers have been authored, the Animation layer can be carried in parallel with other adaptations authoring efforts.
Another level of adaptation occurs outside the OLO and has to do with inter-OLO navigation adaptation. This adaptation is independent of internal OLO adaptations although it relies on similar learner traits such as skill level and prior knowledge. The IDEAL architecture however uses information collected through the individual OLOs Interaction Layer to compute a view (see Kay[20]) of the Learner Model that supports this type of navigation adaptation.
In the next sections we discuss some of the adaptations we are presently capable of introducing or are actively pursuing as research areas.
The first adaptation dimension for OLO is language.Ā The learner model includes his/her preferred learning Language, which, if supported by the OLO, is used for adapting all textual and aural/speech content. Here adaptation amounts to “selection” from pre-existing multi-language content.
The OLO Conceptual layer adaptation sub-layer allows the tagging of each conceptual element down to the individual string level with a language attribute, and multiple language versions of any string are allowed at any level of the Conceptual layerĀ structures.Ā
Note that translation need not be one-to-one on a sentence-by-sentence basis. It is possible to translate whole elements enclosing multiple sentences, besides individual sentences. Here what the languages share are the pedagogic ontology markup elements that will still enclose keywords, descriptions, expositions, examples, paragraphs and other higher level fragments. This also means that for OLOs, language adaptation is happening at a very basic or fundamental level, i.e., at the Concept Layer, as is reasonable to expect.
A second use of text occurs within SVG in the Presentation graphics layer. There text is found on labels and other messages within the text elements. The SVG standard provides an xml:lang attribute that allows the creation of multiple language versions of each string without having to create multiple versions of the same svg graphics document. Because the main purpose is labeling, supporting language at only the svg:text-element level is sufficient for SVG.Ā Note that merging of the Conceptual layer textual parts into the Presentation layer occurs during the authoring of the Sequencing layer.Ā By then the structural relationships in the Conceptual layer text have been exploited; thus, flattening these textual parts as simple svg:text elements is acceptable.
Learning Style [18, 19] adaptation markup within OLOs can be configured to support any major learning style scheme, such as those by Felder[18], Dunn [19],Ā and Gregoric []. For example Felder represents these styles through the five dichotomies: Active/Reflective, Sensing/Intuitive, Visual/Verbal, Sequential/Global, and Inductive/Deductive Learners.Ā The Index of Learning Styles by Felder and Silverman, (available through the Web [18]), provides a simple four-way classification mechanism for learning style estimation based on the administration of a 44 item questionnaire or assessment.Ā
When the Learner registers for a course, the IDEAL system administers an Index of Learning Styles compatible with the Learning Style markup adopted in the Course selected.Ā Thereafter that same ILS could be re-taken at any time the learner logs into the system for starting the use of another OLO.Ā Having taken or retaken the ILS, the Learner is given the opportunity to specify the scope within which his ILS results will be used by being presented with choices for limiting the scope to the current course or allowing the default, which is using the ILS for adaptation across all courses taken.Ā This behavior is in the same spirit of the scrutable learner models proposed by Kay and Holden in [20].
Administration of ILS will many times identify no particularly dominant learning style preference for the learner. To accommodate this phenomenon, the OLO Learning Style adaptation mechanism allows learners to switch to any of the available style adaptations on the fly. This feature allows the learner to reflect on his cognitive strategies, a key step in developing meta-cognitive skills.
The current OLO architecture provides for multimedia resources, such as text and graphics. Future enhancements will include text-to-speech conversion at the client side and embedding of video/audio clips.Ā
Several mechanisms are being investigated to support these learning-style adaptations. First, we have defined a first pass at the inner-metadata adaptation sub-layers that supports these learning-styles. Second, we intend to research the creation of specialized authoring tools that together with the appropriate adaptation metadata can provide consistent guidance in authoring with a particular learning style in mind. A major goal here is to provide as much sharing and re-use of the authored content for different learning styles as possible. Within an OLO, learning style adaptations will result from using the adaptation sub-layers from the Presentation, Animation and Interaction layers. Some of these adaptation opportunities are listed in Table 1 and Table 3.
Any special learning barriers or accessibility limitations on the part of the learner are captured within the LIP record as part of an initial Learner Interview. The OLO architecture emphasis on data-driven configuration and control facilitates supporting the recommendations on accessibility by the WWW Consortium [21], and the IMS Global Learning Consortium [22].Ā Rules for accessibility adaptation are taken directly from those recommendations. These include the adaptation of font sizes and color, the option of automatic text to speech conversion of all the expository material, the provision for alternative text, and alternative Learner input mechanisms. The handling of sizes and colors is particularly easy to adapt using SVG given its scalability features.
Skill level (SL) adaptation requirements introduce another dimension of the OLO where the OLO content is marked-up into overlapping sub-sets that are meant to be appropriate to the learner’s dominant skill level. The adaptation sub-layers for the Conceptual, Presentation, Animation, and Interaction layers are used to mark-up elements in these layers as belonging into any of five skill levels, but play different roles during the authoring and delivery phases.
At the Conceptual layer the adaptation sub-layer skill-level markup is used as hints to authoring tools and to subsequent layers. A key role of the Adaptation sub-layers is to support either the authoring or the delivery of the adaptations. In general the authoring of an OLO will consist of the author choosing a Learning Style and then proceeding through the incremental authoring of each layer for that style. In the process we hope that major portions of the content will be incrementally re-used, although this is not guaranteed.Ā Authoring is essentially an additive task where one vertical strip after another is laid out for each adaptation dimensions for each layer.Ā
The adoption of an a-priori adaptation dimension for authoring reduces the cognitive load on the part of the author and is in no way limited by the adaptation layer.Ā One way of looking at the authoring effort is that of targeting particular sub-sets of the Learner pool.Ā
The skill-level adaptations for the OLO Conceptual layer are currently being introduced by markup attributes on each major markup element within the Conceptual layer, one attribute for each skill level. A TRUE value for the attribute signifies that the element contents is suitable for that skill level. A FALSE value means not suitable, and an INHERIT value means to use the parent element skill markup.
The grammar for the SVG markup language used for Presentation is embedded within some of the tools we use for editing the SVG graphics in that layer. We lack the flexibility to add the same kind of adaptation layer mark-up attributes directly in order to remain compatible with the SVG rendering viewer. Thus in the Presentation layer we have adopted a strategy of wrapping any adaptable graphic shape within an svg:group element which allows assigning an svg:nameĀ attribute as a kind of ID.Ā
Control of such groups on the basis of skill level is achieved by taking advantage of the Animation layer which references, sequences and controls the visibility of these Presentation graphics elements groups by introducing mark-up within the branch and action sub-elements of the Animation layer.Ā This additional group elements and name attributes thus constitutes the Adaptation sub-layer of the Presentation layer.
As a generalization of this idea we are currently exploring the use of Xlink [23] to build a much more robust and independent adaptation layer as a link-database (link-base) of links into the different multimedia portions. Use of Xlink for the adaptation sub-layers will allow the introduction of adaptation markup for all media elements no matter their markup language.Ā Xlink can use Xpath (Xpointer [24] )expressions to identify elements removing the need to retrofit an existing mark-up grammar with additional attributes for adaptation sub-layer since all this information can be stored within the Xlink base document.
To assist authors in maintaining focus during the authoring along a particular dimension, we define a cluster of traits to keep in mind as defining the target learner audience. Clark[6] has defined four (4) architectures of instructions that we plan to use in this way to facilitate the authoring process.Ā These are Receptive, Behavioral, Situated Guided Discovery, and Constructivist Architectures.Ā These allow the authoring of OLO’s to follow clear delimitation of concerns and objectives. Thus these architectures will define authoring guidelines and major authoring tool features.
Our initial Data Structures Course will be authored
following the Receptive and Behavioral architectures.
Subsequent enhancements will support Situated Guided
Discovery and Exploratory.Ā Major portions of the content
developed with the
Receptive and Behavioral architectures in mind, should be
re-usable within Guided Discovery or Exploratory
architectures, either as background documentation or as
tips and explanations.Ā For the Data Structures Course in
particular, we are implementing programming exercises with
a generic OLO that uses servlets to provide remote
compilation and debugging services. This approach falls
within the Guided Discovery and Exploratory architectures
and can be further enhanced by adding compilation error
analysis, static code analysis, and debugging capabilities.
Future support for Discovery and Exploratory architectures
will come in the form of collaborative learning and
collaborative assessment.Ā The IDEAL System can exploit the
analysis of multiple user LIP records for selecting peer
learning and collaboration groups with homogeneous features
that allow making strong assumptions about a group’s
previous knowledge and skill levels.
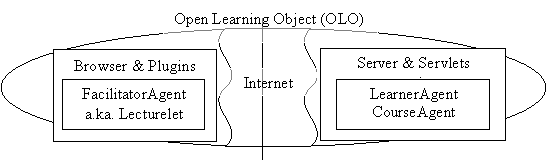
Besides the hierarchical set of content layers and adaptation sub-layers, the OLO’s rely on a programmatic component made-up of generic data-driven Agents. These agents are deployed at the client and the server side and help to balance the computational load. They are the FacilitatorAgent, CourseAgent and LearnerAgent. These are used to deploy a family of OLOs that share a particular set of inner-metadata mark-up languages with similar knowledge capture and adaptation capabilities (see Figure 3).
The client-side architecture for OLO relies on the infrastructure provided by existing browsers and plug-ins. The target browser functionality is that provided by Internet Explorer and Netscape Navigator versions 4.00-5.5.Ā This includes the capability to support the Adobe SVG Viewer. These target browsers support a sub-set of the DOM Level 2 [25] specification that is sufficient for the dynamism and interactivity required from the OLO client-side architecture.
Each multimedia type is supported through the installation of a corresponding plug-in.
Each OLO includes Browser and Plug-in detection capability. When a plug-in is not installed the OLO will offer to install it following standard procedures.Ā
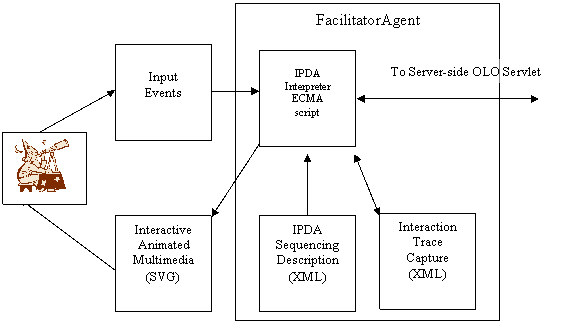
The current OLO Client-side architecture can be classified as that of a Situated MicroAgent [26, 33] playing the role of FacilitatorAgent.Ā Formally it is an Interface Push Down Automaton (IPDA)[27] implemented through an interpreter, and programmed for reactive (situated) behavior using a data-driven approach. This FacilitatorAgent provides learner-side interactivity and animation using a state-sequencing specification derived from the Animation and Interaction layers.Ā The interpreter portion of the FacilitatorAgent is coded using generic ECMAscript code that is downloaded as part of the client-side OLO.Ā The general structure of the OLO Client-side architecture is shown in Figure 4, and each block is described in what follows.
 Ā
Ā
The interpreter receives or traps all events generated by the mouse or any other input-forms widgets contained within the OLO user interface as defined in the Interaction Layer.Ā The Interpreter has access to the Presentation layer DOM tree representation to effect dynamic changes to that layer which is then rendered by the SVG Plug-in. Usually a dedicated ECMAScript function is included for each type of event that can be generated from an active shape in the defined UI. These event handlers record the event into an Events Stack and invoke the IPDA interpreter. The IPDAI inspects the Events Stack for new events. Upon finding some events it searches each branching condition on the current-state as described in the Animation layer sequence description, trying to match the branch predicate.Ā If a sub-set of stack events match a branch-Condition, the IPDA will transition into the new State and apply the action indicated by that branch.Ā
The Interaction Trace is a record or log of all the events originated throughout the interaction with an OLO. These events are annotated with their absolute time of occurrence and with the state the OLO was in when the events occurred, and optionally with the destination state if a branch was triggered as a result of that event.
State transition is accomplished by identifying the branch being taken from the current state, and pushing the current state and the current values of the DOM nodes to be changed into a Backtracking Stack. The next state indicated by the branch and any incremental updates specified by it are applied within the DOM tree-representation. This causes the Browser and Plug-ins to update the rendered view of the DOM tree. Once the incremental changes are inserted, the new state is marked as the current state.Ā When operating the animation in autopilot mode, the IPDA interpreter will start a time-out function that takes as arguments a time-out handler and a number of milliseconds specified in the state duration attribute. The interpreter then waits until activated again by either the time-out or user initiated events.
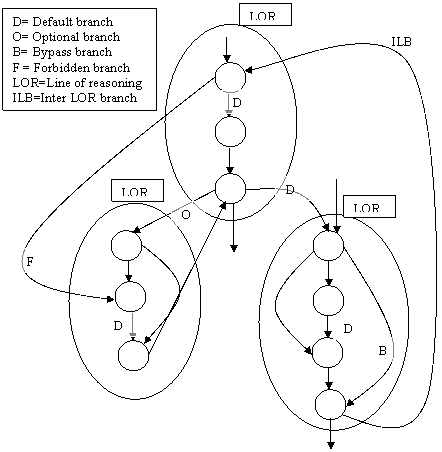
Automatic time-out driven animation is possible because the set of OLO states are arranged into a default traversal sequence (see Figure 5). This default traversal is identified by a branch type attribute with a value of “default”. The default branches have a special meaning in that they represent the minimal incremental change into a new state that an OLO author considers as stable and meaningful for a given learner.
Some branches may by-pass several intermediate states (linked through their default branches).Ā These by-passing branches do not need any associated actions. Instead the changes are specified through the sequential application of all the actions associated with the default trajectory linking the origin and destination state of that branch. The net effect over the Backtrack stack is as if those intermediate states had been visited with a zero duration time. Keeping a Backtrack stack makes it possible to go back into those states if so defined in the animation sequence or as requested by the learner.Ā
Each branch may indicate several parallel actions. These identify the sub-documents, the elements within those documents that are to be impacted, and the specific update values for those elements.
TheĀ Animation is organized as a two level hierarchy. Besides primitive states we have macro states called Line-of-Reasoning(LOR) states. A LOR encapsulates a logical argument or explanation that should run through-out all its primitive states in order to be complete and make sense. The LOR idea is close to the concept of Script as defined by Schank [28].
An important role of the Animation adaptation sub-layer is to specify how to steer the flow between these LORs adaptively. Both whole branches and individual actions within any branches can be tagged with styles/skills selection elements to further condition the branch. The skills and styles sub-elements embedded within branch elements function as a matrix of switching blocks for those branches. A default branch is then one where all the skills/styles elements hold their default values. When a branch has a style or skill markup element that does not match that of the current learner, no branch takes place. When an action style sub-element does not match that of the learner, the parent branch may occur, but no action takes place.
Default branches from states inside an LOR macro-state into a state outside that LOR are since prohibited, they do not make sense from a narrative or reasoning standpoint.
Optional branches into optional LOR macro-states can be introduced at any state (although usually at the end states of an LOR sequence). Note that LORs are not intrinsically “optional” but are made so by the kind of branch that is used to enter them. The end state of an LOR entered through an optional branch should always branch back to the state where the original optional branch into that LOR was initiated. This behavior enforces the principle that optional LORs are incidental to the main exposition argument of the OLO.Ā The set of LORs that is traversed following default branches exclusively is called the back-bone traversal, and is the minimum set of states that exposes the core set of concepts embodied by that OLO. It is expected that learners from all classifications will (at least) follow this back-bone traversal.
The Facilitator Agent is also responsible for resuming a suspended OLO.Ā In this case the OLO downloaded will include a non-empty Interaction Trace as an additional learner-specific document. By rehearsing the sequence of states in the Interaction Trace starting from the initial state the agent is able to resume the OLO in the same state as when it was suspended.
Although the current form of the FacilitatorAgent is that of an interpreter for an IPDA automaton, other more sophisticated and intelligent Agent architectures are possible. In particular architectures that, besides the current purely reactive or behavioral layer, also implement a deliberative layer involving planning, (i.e. Believe-Desire-Intentions (BDI)[29]).Ā More intelligent agent architectures are needed for OLOs designed following more complex architectures of instruction such as Situated Guided Discovery and Exploratory.Ā The current IPDA automaton provides a mechanism to test the development of the IDEAL infrastructure. We expect to continue to experiment and introduce more complex OLOs and more intelligent FacilitatorAgents within this infrastructure
The User/Learner interface is made of two parts, a standard UI made of the minimum set of buttons necessary for simple forward-backward-auto navigation, and an OLO-specific part.Ā The OLO-specific part of the UI depends on the OLO presentation layer graphic objects. SVG allows the detection of primitive mouse and keyboard events, and the embedding of event handlers that will be invoked by these contextualized semantic events.
One of the main goals of the OLO Architecture is to provide a standardized and open mechanism for capturing and making accessible outside the LO the results of the interaction between learner and LO.
This interaction is dependent on the particular user interface that the LO presents to the Learner, and its meaning is contextualized by the LO itself.Ā Thus in general we cannot determine in advance the ultimate form of such interaction trace, but we can define a basic mechanism that is sufficiently general and that depends on the OLO itself to contextualize and assign meaning to the trace.
The interaction trace can thus be seen, first, as LO-independent primitive interaction events and, second, as LO-specific semantic events as interpreted in the context of the LO.
Primitive interaction events will include the click of a mouse button while at some coordinated or the typing of a keyboard key.Ā LO-specific semantic events will include interacting with particular graphic shapes and the transition to a new LO-state as a result.Ā
Note that all events are time stamped and captured within the Interaction trace even when no branches are activated. This is important to identify and diagnose OLOs which may be prompting erratic behavior from the learner.
An OLO loading event is added to the interaction trace when the OLO is loaded. This event is associated with the initial state. When an OLO is suspended, a suspend event is added to the trace with the time of suspension. Similarly when an OLO is re-started, a resume event is generated to account for the event.
The Interaction Trace is an open and permanent record of the learner’s interaction with the LO and is sent to the server-side LearnerAgentĀ as a form post method operation. At the server-side the interaction trace is persistently stored as part of the Learner Information record(LIP) in the XML database (dbXML).Ā The interaction trace is saved upon completion of the OLO, or whenever the learner suspends his interaction with the OLO. This allows restarting the OLO in the same configuration as when it was suspended.
Every primitive event and state transition event is time-stamped using absolute time with a resolution of milliseconds. Because time-stamping occurs at the client-side there is very little latency between the actual event and the reported time-stamp. ĀWhen an OLO is re-started, the restart time is included via a resume event associated with the state in which the OLO is restarted, this should be the same state in which it was suspended. Subsequent time intervals are measured with respect to the resume event time.
The Lerner Interaction Trace information can be data-mined to identify patterns that indicate important features of a group of learners or for a set (i.e. a Course) of OLOs.
For individual learners the trace is used to assess his Learned Score by measuring the total time taken to complete a learning object and time taken to review as described in [11]. For the OLO, traces from a group of users can be statistically aggregated to identify problems with particular portions of that OLO, especially when the learners might be taking excessive time to reply/react to some portions of the LO. This could indicate that such portions need to be reviewed by the authors and improved. This is a key feedback facility to support continuous OLO improvement.
Trace data can be used to verify the readiness level or deficiencies of a group of Learners in collaborative environments. One such use is in hybrid eLearning/Traditional learning environments [30] where the OLOs are being used as homework to ready the students for the in-classroom discussion of the more exceptional or difficult material. This material is quickly and just-in-time identified prior to classroom intervention. Thanks to OLO raw trace data capture, this data can be reduced through the detailed group summarization capabilities of other Agents in the IDEAL system.
The Server-side OLO architecture primary objectives are:
Navigation adaptations are based on OLO relationships and on the learner model. Each OLO has an associated LOM record as defined by the LOM standard that contains several “relations” elements identifying several types of relationships with other LOs. Using this information and the information in the Integration layer document also referenced within the “technical” element of the LOM record a CourseAgent dynamically assembles into an HTML document the OLO being delivered to the browser.
The FacilitatorAgent collects learner interaction trace data and sends this to the LearnerAgent on the Server. The LearnerAgentĀ uses the IDEAL Learner Information System (LIS) to store this learner interaction trace, outcomes assessment results, and ILS styles inventory into the Learner Information Packaging record. This information is subsequently processed by the LearnerAgent which computes the Learned Score for each OLO and the skill-levels vector based on OLO assessments results. The LearnerAgent is also responsible for Learner authentication and authorization and for administering the ILS and initial personal profile interview.
Adaptive navigation [32] seeks to present the LOs associated with a course in an optimum order, where the optimization criteria takes into consideration the learner’s prior knowledge and performance in related LOs.Ā Previous work [32] on adaptive navigation has modeled the user knowledge about a topic (LO) as falling within four boolean categories: not-ready-to-be-learned, ready-to-be-learned, in-work, and learned. The IDEAL system extends this discrete metrics by computing a LearnedScore real value for all predecessor LO as a function of several other basic metrics, such as LO review time, and performance scores [11]. Then it combines these into a weighted sum (Readiness Score) based on the relation weight for each predecessor LO. The adaptive navigation algorithm is sketched in Table 6Ābelow.
This navigation will seek to cover those LOs with the highest Learner Readiness Score first. The IDEAL system metric measures how well prepared a Learner is for attempting to learn a given LO. It is computed based on the Learner Score on all predecessors to that LO weighted by the dependency weight of the relation.Ā
/* OLO Adaptive Navigation Algorithm */
/* Prioritizing traversal of LO Space DAG graph */
/* using the Readiness Score metric */
FindSuccessor( node(i)) {
if( succList.isEmpty() )
succList = node(i).getSuccessors();
for-each ( node(j) in succList ){
if( node(j).isLearned() ){ /* already (recursively) learned */
succList = succList.remove (node(j)) /* remove nodes learned*/
continue; /* grab next node(j+1) */
}
predList(j) = node(j).getPredecessors();
readinessScore =0;
for-each ( node(k) in node(j).predList() ){
readinessScore += node(j).weight(node(k)) * ( node(k).perfScore() );
}
node(j).setReadinessScore(readinessScore); /* compute r.s. of succ. */
}
maxNode = succList.getMaxReadinessScore();
succList = succList.remove (maxNode) /*remove node to be learned*/
return node(maxNode) ; /* there is always a maximum */
}
|
Open Learning Objects leverage the power of XML inner-metadata for simplifying the tasks of learning object content adaptation, learner interaction trace capture, learner modeling, and adaptive navigation. OLOs complement other components of the IDEAL eLearning environment, such as the LOVE Learning Objects Virtual Exchange, the Assessment Authoring System, and the Learner Information System.Ā Together these constitute a powerful and secure platform on which to undertake development of eLearning courses. IDEAL is totally based on open sourced public domain tools and standards such as Apache Http server, Tomcat Servlet Container, dbXML, SOAP, publicly available tools for SVG and generic XML authoring.Ā The OLOs hierarchical architecture with a clean separation of concerns, its use of open XML DTD for all its layers, the data-driven emphasis, generic Agents, and the use of public domain tools and markup languages, earns, in our view, the “Open” adjective for the Open Learning Objects.
[1] IMS Global Learning Consortium, IMS Learning Resource Meta-Data Information Model,Version 1.2.1 Final SpecificationĀ (OnLine) http://www.imsglobal.org/metadata/imsmdv1p2p1/imsmd_infov1p2p1.html
[2]Kay, J.,Kummerfeld, B., Adaptive Hypertext for Individualized Instruction,Proceedings of the Workshop on Adaptive Hypertext and Hypermedia, User Modeling’94,Cape Cod, August 1994.
[3]ĀBrajnik, G., Tasso, C.,Ā "A Shell for Developing Non-Monotonic User Modeling Systems", Int. J. Human-Computer Studies 40, pp. 31-62, 1994.
[4] Minio,M., Tasso,C.,, "User Modeling for Information Filtering on INTERNET Services: Exploiting an Extended Version of the UMT Shell", Proceedings of the Fifth International Conference on User Modeling, Hawaii, January 1996
[5] Eklund, J. and Brusilovsky, P., “Individualising Interaction in Web-based Instructional Systems in Higher Education”, Proceedings of The Apple University Consortium's Academic Conference, Melbourne, Australia, September 27-30, 1998
[6]Clark, R., Four Architectures of Instruction, Performance Improvement Nov-Dec-1999, [Available OnLine] http://www.clarktraining.com/research/4architectures.pdf
[7] IMS Global Learning Consortium,IMS Question & Test Interoperability Specification, http://www.imsglobal.org/question/index.html
[8] IMS Global Learning Consortium, IMS Learner Information Package Specification, http://www.imsglobal.org/profiles/index.html
[9] IMS Global Learning Consortium, IMS Content Packaging Specification, Āhttp://www.imsproject.org/content/packaging/index.html
[10] El Saddik, A., Ghavam, A., Fischer, S., Steinmetz, R., Metadata for Smart Multimedia Learning Objects, ACE 2000, Melbourne, Australia, ACM SIGCSE
[11] Shang, Y. and Shi, H. IDEAL: An integrated distributed environment for asynchronous learning, Distributed Communities on the Web, LNCS, No. 1830, Kropf et al (ed.), pp. 182-191.
[12] Fielding, R.T.,Architectural Styles and the Design of Network-based Software Architectures,Ā Doctoral Dissertation, http://www1.ics.uci.edu/~fielding/pubs/dissertation/top.htm
[13]Chen, S.,et al., Personalizing Digital Libraries for Learners, in Proc.12th Int’l Conf. Database and Expert Systems Applications (DEXA'2001), Munich, Germany,September 2001.
[14] Self, J.A., "Bypassing the intractable problem of student modeling",Ā In Frasson, C., & Gauthier, G. (Eds.), Intelligent Tutoring Systems: At the crossroads of artificial intelligence and education, Ablex Publishing, Norwood (1990) 107-123.
[15]Shi, H.,Shang, Y., and Chen, S., Smart Instructional Component Based Course Content Organization and Delivery, in Proc. 6th ACM Int’l Conf. Innovation and Technology in Computer Science Education,Canterbury,UK, June 2001.
[16]Shang,Y., Shi, H., and Chen, S., Agent technology in computer science and engineering curriculum, in Proc. 5th ACM Annual Conf. on Innovation and Technology in Computer Science Education, Helsinki, Finland, 2000, 120.
[17]Shi,H., Shang, Y., and Chen, S., A multi-agent system for computer science education, in Proc. 5th ACM Annual Conf. on Innovation and Technology in Computer Science Education, Helsinki, Finland, 2000
[18]Felder, R. M. and Silverman, L. K.,Index of Learning Styles (ILS), http://www2.ncsu.edu/unity/lockers/users/f/felder/public/ILSpage.html.
[19]Dunn,R., How to Implement and Supervise a Learning Style Program, Association for Supervision and Curriculum Development, ASCD, 1996
[20] Holden,S., Kay,J., The Scrutable user model and beyond, Proceedings of the Workshop on Open, Interactive, and other Overt Approaches to Learner Modelling Organisers: Rafael Morales, Helen Pain, Susan Bull and Judy Kay, 9th International Conference on Artificial Intelligence in Education Le Mans, France 18 July 1999
[21]W3C Consortium, User Agent Accessibility Guidelines, 1.0 Working Draft,22 June 2001, (On Line)Ā http://www.w3.org/TR/2001/WD-UAAG10-20010622/
[22] IMS Global Learning Consortium,IMS Guidelines for Developing Accessible Learning Applications Version 0.6 White Paper, (On Line) http://www.imsproject.org/accessibility/accwpv0p6/imsacc_wpv0p6.html
[23]DeRose, et.al. , XML Linking Language (Xlink) Version 1.0,Ā http://www.w3.org/TR/xlink
[24]Daniel,R., DeRose,S., Maler,E., XML Pointer Language (Xpointer) Version 1.0, http://www.w3.org/XML/Linking.html
[25] W3C Consortium, Document Object Model (DOM) Level 2 Core Specification, Version 1.0, W3C Recommendation 13 November, 2000
[26] Rosenschein, S.J., Kaelbling, L.P., A Situated View of Representation and Control, Artificial Intelligence 73, 1995
[27]Olsen, D.R., Pushdown automata for user interface management, ACM Transactions on Graphics, Vol. 3, No. 3, July 1984
[28]Schank,R.,Abelson,R., Scripts Plans Goals and Understanding,Ā An inquiry into Human Knowledge Structures, Lawrence Erlbaum Associates, Publishers, 1977.
[29] Winikof, M.,Simplifying Agent Concepts, RMIT University and Agent Oriented Software, Australia, http://goanna.cs.rmit.edu.au/~winikoff/PPT/sri-5-june-2001/sld001.htm
[30]Novak,G. M., Patterson, E. T., and Gavrin, A. D., Eds., Just-In-Time Teaching :Ā Blending Active Learning With Web Technology , Prentice Hall, 1999.
[31] Leidig, T., L3-Towards and Open Learning Environment, ACM Journal of Educational Resources in Computing, Vol. 1, No. 1, Spring 2001, Article #5, 11 pages.
[32] Brusilovsky, P., Adaptive and Intelligent Technologies for Web-based Education, In: C. Rollinger and C. Peylo, (eds. Kanstliche Intelligenz, Special Issue on Intelligent Systems and Tele-teaching, 1999, 4, 19-25
[33] Weiss, G. (Editor), Multiagent Systems: A Modern Approach to Distributed Artificial Intelligence, The MIT Press, 1999