To prepare their lessons, foreign language teachers have been using audio and video contents for many years. The WWW can provide them with many newly updated contents. However, preparing multimedia lessons with such contents can be time consuming and these contents may not be exactly adapted to their pedagogical objectives or to their pupils' skills. This paper presents on-line facilities to help teachers in this task and shows how hypermedia technology can help pupils to better understand videos. All these developments are based on the extraction of the closed caption transcription of videos and the analysis of this text by Natural Language Processing techniques. A system prototype has been built to validate these ideas and to carry out various experiments with real teachers.
on-line education service, foreign language teaching, video indexing, hypermedia, natural language processing.
To prepare their lessons, foreign language teachers have been using audio and video contents for many years. The main reason for this is undoubtedly that they motivate their pupils by associating lively pictures with speech.
Thanks to new on-line video services like Fast TV or broadcaster Digital TV web sites, the WWW provides teacher with a huge source of new and up-to-date video materials [URL1][URL2] . Broadcasted contents can also be digitally recorded with systems like those provided by TIVO or Replay TV [URL3][URL4]. By being locally recorded or streamed on a remote server, videos can be accessed from the WWW or from a local school intranet using high speed connections.
These new on-line contents are often closer to reality than purely educational contents. They also give pupils direct access to the way a language is spoken. As quantity gives rise to diversity, each pupil should be able to find interesting topics. But this quantity makes selection harder. All the accessible contents are extremely diverse in quality and particularly in the level of ease of understanding these contents. Aggregating contents with video to construct lessons takes teachers a considerable amount of time.
These reasons motivate our work to provide value-added services on on-line video contents.
Following interviews with French teachers of English, it appears that some teachers prepare lessons with video contents and associated information found on the net. Nowadays, videos are most frequently recorded with a plain VCR from cable or satellite TV, but associated information like transcription is effectively found on the broadcaster's web sites. With the development of high speed internet connection everywhere, we can expect that videos from the WWW will be used more and more.
The goal of our work is to provide facilities to teachers for the preparation of such multimedia teaching activities. More precisely we have developed facilities for:
To provide these facilities we extract and use video closed caption encoded information. It is used to index videos, to generate grammar exercises automatically and to help pupils navigate through videos and understand them.
This paper presents our developments. The first section outlines the global architecture of our system. The second presents our experimental video library. The third section explains how we linguistically analyse the closed caption extracted text to get the necessary information. The following section describes the computation of pedagogical indexes, which are used to search for videos adapted to specific lessons. We will then explain how we regenerate the video content using SMIL format to complete the closed caption video with hyperlinks. These hyperlinks will be used to navigate through the video and to access dictionary definitions. The automatic generation of gap-fill exercises with video transcription is detailed in section 6. Finally, the last section includes our conclusion along with a presentation of our current experiment.
To develop and test our ideas, we have built an experimental prototype of an on-line service.
The global architecture of this prototype is as follows:
We have:
Other machines are used for back office processing. The main processes of our system are the following:
The digital video library and the above processes will now be described more precisely in the following sections.
The first issue we took into account when dealing with videos was not technical but legal. Managing a video library or dealing with video contents can sometimes raise copyright issues. We are aware that some parts of our processes might necessitate agreement from the owners of the videos. The purpose of this paper is not to specify the agreements required (see for example [URL5] for US copyright law). It is more specifically aimed at showing what kind of facilities can be provided for teachers to help them use videos in the classroom. We believe that such agreements may exist for educational purposes. For example, in France, an agreement has been concluded between the French Ministry of Education and the BBC to allow French teachers to use BBC World contents. All this information confirms our expectations. The existence of all necessary agreements is presumed for the following sections of this paper.
To conduct our purely research-based experimentation, for internal use only, we didn’t have to take into account these legal considerations. To build our experimental video library, we used a Digital TV recording system. We recorded various American broadcasted TV programmes from public channels. We tried to select very different kinds of contents in order to evaluate with teachers which kind was the most appropriate for each level of pupil. Our selection included the news, interviews, cartoons, sport, film sequences and scientific, historical and geographical documentaries.
We extracted fifty short sequences, each about 5 minutes long. Next, these sequences were encoded in the Real Video format in order to be streamed. We chose a 500 Kb/s encoding format.
For each programme, we also extracted some meta-data such as title, date, broadcasting channel, and so on, from the TV programme service provided by the Digital TV recording system company. This meta-data information is stored in the database of our digital video library. They are displayed in the results of our video searching service.
All of our work is based on the use of closed captioned text encoded in broadcasted videos. The extraction of the text is carried out by specific devices and software and is a common process (see for example[1]).
Once this file is extracted, it is filtered in order to only keep the text that is related to speech parts of the video contents.
Next, this text is processed by a Natural Language Processing tool that produces all the information necessary for producing our video navigating tools, pedagogical indexes of videos and grammar exercises.
Natural Language Processing (NLP) is a subdiscipline of both computer science and linguistics, dealing with human-language analysis, understanding, generation and translation. Nowadays, there is a variety of software available for performing the following three steps:
This consists of segmenting the input text in a sequence of tokens; each token corresponding to a coherent unit, such as a word, a number, an email address, etc. Paragraph and sentence cutting of the text may be done simultaneously during this step.
This step consists of retrieving morphological and lexical data on each token in a computerized lexicon. Unknown tokens which look like words may be submitted to corrective methods. Morphological data may be pre-defined for tokens such as numbers (which are likely to behave either like a noun, an adjective or a determiner, but never like a verb or a preposition). Most words are ambiguous, so each token is likely to have several lexical analyses.
This step consists of assigning each token with:
Part-of-Speech tagging can be done through statistical or rule-based methods. [3] [4] [5]
We have developed our own set of NLP software tools that efficently perform these three steps: a tokenizer, a lexical analyser (with corrective methods) and a rule-based part-of-speech tagger designed to split a sentence into chunks corresponding to minimal phrases [2]. Each chunk is built on the part-of-speech tags. The tagger chooses a sequence of chunks recovering the sentence, selecting at the same time one tag for each word. We have also created data such as lexicons and grammars to make these tools work in several languages (French, English, Spanish, etc.). For the purpose of the experiments with our video library just with American contents, we only used English data. Let's consider the following sentence:
"Fall turned to winter."
"Fall" and "winter" may be both either a noun or a verb. However, in this context, lemma of the word "Fall" is "fall", its Part of speech is Noun. The lemma of "turned" is "(to) turn", its Part-of-speech is Verb. The lemma of "winter" is "winter", its Part-of-speech is Noun.
The Part-of-Speech tags produced may be more or less descriptive. Our rule-based Part-of-speech tagger uses a tagset based on the MULTEXT specifications for the lexicon encoding [URL6] . The tag first letter is a symbol for the word Part-of-speech. Each other letter stands for a particular morpho-syntactic property. These properties are:
For instance, in the previous example, "fall" should receive the tag Ncs (N for noun, c for "common, s for "singular)". "Turned" should receive the tag Vmids3 (Verb, main, indicative, past, singular, third person).
We use this part-of-speech tagger to analyse the texts extracted from the videos in our video library. The three steps described below are performed successively and the results are obtained in an XML-type format. Here is an example of such a result which corresponds to the tagging of the part of a sentence of a text from one video:
<PHR TXT="00:01:00.06\00:01:01.15 AUSTRALIA WAS FIRST DISCOVERED 00:01:12.06\00:01:14.23 BY DUTCH MERCHANTS IN 1606 . ">
<ST CAT="GN-NP" STR="PRENOM">
<TER SEG="00:01:00.06\\00:01:01.15" POS="77 78" TYP="TIMECODE" FLE="00:01:00.06\\00:01:01.15" LEM="00:01:00.06\\00:01:01.15" CAT="NON-VU" TRA="MUL/?" GRA="?" CPT="00:01:00.06\00:01:01.15"></TER>
<TER SEG="AUSTRALIA" POS="78 79" TYP="MOT" FLE="AUSTRALIA" LEM="Australia" CAT="GN-NP" TRA="MUL/Npµµ NOMBRE/SINGULIER" GRA="Npµµ" CPT="Australia"></TER>
</ST>
<ST CAT="GV-PT" MODE="INDICATIF" TEMPS="PRETERITE" STR="PERSONNE/1PRS/3PRS GENRE NOMBRE/SINGULIER">
<TER SEG="WAS" POS="79 80" TYP="MOT" FLE="WAS" LEM="be" CAT="GV-ET" TRA="SC_OK PERSONNE/1PRS/3PRS NOMBRE/SINGULIER MUL/Vbids[13]p COUTTERM/41" GRA="Vbids[13]p" CPT="$be_3 $be_2"></TER>
<TER SEG="FIRST" POS="80 81" TYP="MOT" FLE="FIRST" LEM="first" CAT="R" TRA="MUL/Rµ" GRA="Rµ" CPT="$first_10"></TER>
<TER SEG="DISCOVERED" POS="81 82" TYP="MOT" FLE="DISCOVERED" LEM="discover" CAT="GV-PPA" TRA="TRANSITIF/1 SC_OK MUL/VvpdŁŁp COUTTERM/46" GRA="VvpdŁŁp" CPT="$discover_2 $discover_1"></TER>
The tag PHR stands for sentences, ST for chunks. Each word description is inside a TER tag. This tag has the following fields:
On the chunk level, we create special features for the morpho-syntactic properties we wish to index. This is done automatically by the tagger. For instance, the verb mode is given in the MODE attribute of the ST tag.
The time code information, contained in the extracted text,
appears in the results as a special type of token. They are identified
by the value "TIMECODE" for the TYP attribute of the tag
The developments presented in the following sections use this XML formatted information.
Finding appropriate video contents for specific pedagogical objectives can be considerably time consuming. Videos are much longer to view than a set of HTML pages, and teachers don’t necessarily take the time to view many videos before finding the right one. That’s why we developed a digital video search engine that allows teachers to select videos according to pedagogical oriented features.
Usually videos in digital libraries are manually indexed. But video contents are particularly difficult to index as one needs to take the time to view the content before being able to describe it. Such a manual process is thus not always efficient enough to cope with the dynamics of new video contents becoming available on-line or broadcasted on any satellite or cable TV channel.
More automatic procedures use the closed caption information to index video contents [1]. But the computed index only allows users to find videos by submitting keywords that must belong to the extracted closed caption text.
Other sophisticated techniques index videos with features computed by processing the signal composed of samples of images of the video. But the only way to submit a query to such a system is to provide a representative image of the video you are looking for.
What teachers need is more specific indexes that allow them to find videos adapted to the pedagogical objectives of their lessons and to the skills of their pupils. This is why we have developed some algorithms to compute indexing features that are relevant to the difficulty of a video that is intended to be understood and to the skills that pupils need to have in order to understand it. These features are the following:
Although they are automatically computed, teachers should be able to send their own evaluation in order to change the computed values, if necessary.
Let us now specify how these features are computed.
To compute the speech speed feature, we first count the number of syllables of the words found in the closed caption text between each time code. Each time code is kept as specific words in the result of the text analysis and the tagging of each word helps the counting process. To compute the number of syllables of a word we approximate it by counting the sets of successive vowels found in the word. We subtract 1 from this number if the last group of vowels is composed of a single silent vowel (for example “e” for French and English).
To obtain a speed measure, we divide this number of syllables by the time elapsed between the two time codes. Next, we keep only a portion of the greatest values in order to eliminate values which correspond to parts of the video with music or noise without any speech.
Finally, the average speed is compared to predefined thresholds in order to ascribe a speech speed feature to the analysed video.
For example, the value of the speech speed feature will be:
These thresholds are specified in the service configuration. They can be defined from a sample of videos that are manually evaluated by voluntary teachers.
We compute the vocabulary level by using several defined lists of words. Each list represents a sample of the vocabulary managed by pupils with a particular skill level in the learned language.
To define these lists, we used corpus-based analysis to define the most currently used words. For example, such corpus analysis already exists for the English language. [URL7]
Next, we presupposed a number of words that should be known by each level of pupils. Finally, we selected the appropriate number of words, in order of frequency, to define the vocabulary list for each level of the pupils under consideration. Each word in these lists is in its lemma form.
To calculate a vocabulary level of a video, we count the proportion of words in the closed caption text found in each list. To compare the words in the list and in the text we used the lemma form of the words computed by the NLP tool.
Various rules are then applied to decide which level of difficulty is ascribed to the video. For example, the value will be:
PBeginners and pModerate represent the proportion of words found in the vocabulary defined for beginners and moderate pupils. PSpecialist is the proportion of words not in any list.
Here again, these rules can be defined from a manually evaluated sample of videos.
The last computed feature used to index the videos is the grammar profile. This feature is composed of the principal grammar forms found in the closed caption text.
Grammar forms can be :
These grammar forms are detected from the tagging result of the linguistic analysis. The only thing to do is to count the number of times a form is found in the text while parsing the XML result of the natural language processing tool. If this number is higher than the threshold defined for each form, then the form is included in the grammar profile.
Once these features are computed, they are recorded in a database in order to be able to search videos having specific values for those features.
We also provide more conventional ways of searching the videos by thematic domain selection and keywords requests. All these features can be combined to search videos. The database contains all information necessary to process these requests. It stores all the words found in the closed caption extracted text in their lemma form. These words are computed by the NLP tool and scored by a conventional text indexing tool. They are completed with some thematic domains that are also ascribed to the video by the NLP tool using text automatic classification algorithms.
Before being indexed, each video is registered in the database with a unique identifier. This identifier is also used to compute the URL to be accessed in order to view the video.
To search a video, users submit their request on an HTML form accessible through the Web. The provided answers contain the video hyperlink to view the video and a video description with its title, length, thematic domains and all the values of the computed pedagogical features. All this information helps the user to choose the right video s/he needs among the answers without viewing the videos. This should help teachers and save time.
Now that the videos can be easily found by teachers to prepare lessons, we thought it seemed appropriate to develop some facilities to help the pupils understand a video and navigate through it.
It is very helpful to show the closed caption text of a video when trying to understand what is being said.
It helps you to match sounds with words. However, sometimes pupils don't know the meaning of the words. That’s why we thought it would be useful to give pupils direct access to the dictionary definition of words within the closed caption text.
We also thought that pupils would sometimes need to listen again to certain spoken sentences of the video. Pupils would therefore need to stop the video and rewind it to the beginning of the sentence. We have all experienced the difficulty of using a scrollbar to navigate in a video. That's why we added an arrow picture to the video screen. You simply have to click on this arrow picture in order to position the video to the beginning of the sentence being said.
This navigation arrow and access to definitions have been included as hyperlinks to the closed caption text that is shown to the user. In order for these hyperlinks to work correctly and for the closed caption text to be shown synchronously with the video, we automatically generate two files for each video in the digital library. The first one synchronises the two channels composed of the video and the closed caption text. To do this, we use the W3C SMIL format recommendation [URL8]. The second file includes the closed caption text with hyperlinks for the main words and for the arrow navigation. For this step, we use the Real Text format (RT) defined by RealMedia™.
The generation of the SMIL format is straightforward. It only includes the framing of the display and the channels to include. However, the RT file is generated by parsing the XML result of the NLP tool. This parsing is then used for the following tasks. Firstly, it filters TIMECODE tokens to generate text synchronisation information. Secondly, the morpho-syntactic information included in the tagging of each word is used to compute the URL of the right definition of the word. We first use the lemma form of the word as the word entry point in the dictionary. Yet this lexical reference is not precise enough to have the appropriate definition. Indeed, several definitions might be available according to the "part of speech" of the word (adjective, noun, verb). For example, the word “fly” has different definitions if used as a noun or as a verb. We then go one step further by selecting the right definition which corresponds to the word's "part of speech" that it is actually found in the closed caption text. To have this specific definition directly accessible with a URL, we put a Merriam Webster Dictionary HTML version on an HTTP server [URL9]. Thirdly, the sentence tag (PHR) and token type for TIMECODE are used to identify the nearest time code in the video before the beginning of each sentence. Each time a new sentence is detected, the command associated by the arrow navigation is modified. This command calls a function defined in the API of the plug to the RealMedia player. This function asks the player to start the video at the nearest time code before the beginning of the sentence.
The SMIL file is retrieved by the user to view a video. The RM video file and the RT file are then called to be synchronously displayed. It is interesting to note that both these files are accessed with a URL and, therefore, can be stored in different locations. For example, the video can stay on a streaming server managed by the owner of the videos' copyrights.
All generated SMIL files are accessible with a dynamic URL computed with a video identifier. These URLs are used by the video search engine to display its answers.
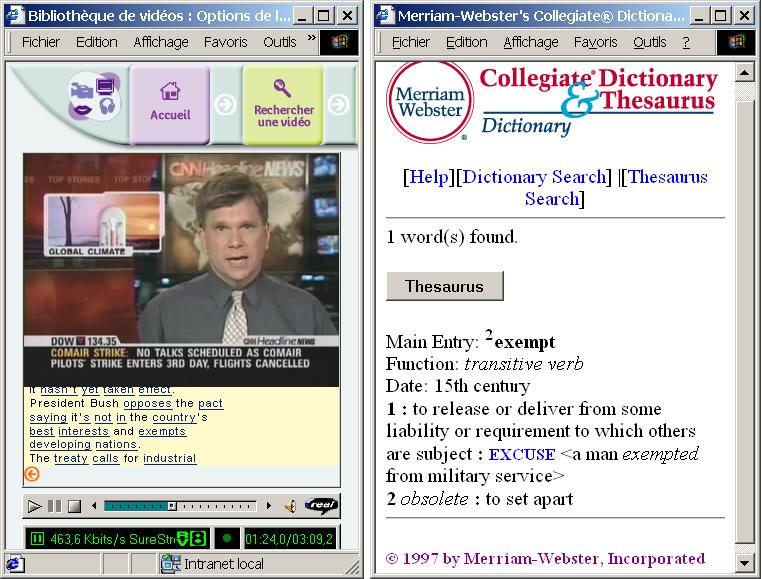
The following picture shows a screen shot of two windows. The one on the left side includes a generated closed captioned video being viewed. The text with underlined words is the generated closed caption text. At the bottom of the text, we can see the navigation arrow that allows users to go to the beginning of the sentence currently being said. The window on the right results from the selection of the word “exempts” in the closed captioned text . It shows the right definition of the verb “exempt”, whereas the first definition in the dictionary is that of the noun and the second that of the adjective.
Gap-fill exercises are used by language teachers in order to test their pupils' lexical, syntactic or general knowledge. A gap-fill exercise is a text within which words or sets of words have been removed. Various software is currently available to help teachers edit and evaluate such exercises [URL10] [URL11]. However, teachers are obliged to choose themselves the words that are to be removed.
Our proposal is to automatically create gap-fill exercises that test morpho-syntactic knowledge. Although this can be applied to any text, we thought that generating exercises with the video closed caption encoded text would be more interesting for pupils.
The procedure comprises two steps:
This step is carried out as described in the third section. The XML formatted result was too verbose and was not adapted to the pattern marching process we have developed. We therefore generate a simplified one. Here is an example of this format for the same sentence as the one already shown.
Example 1: Simple part-of speech tagging
"Australia was first discovered by Dutch merchants in 1606."
Australia/Australia/Npµ. was/be/Vaids3 first/first/R. discovered/discover/Vvpd- by/by/S. Dutch/Dutch/Ap. merchants/merchant/Nc.p in/in/S. 1606/NBR/Dk.p
In this annotated text format, each word in the text has the following structure: word/lemma/encoded_morpho-syntactic_features
We use this compact format to generate gap-fill exercises by carrying out the following steps:
This is done by applying pattern substitution rules to the annotated text.
These rules are composed of two parts: the pattern to be found and the way to substitute it.
A pattern is an ordered set of items. Each item is made of a word (optional), a lemma (optional), and a more or less complete morpho-syntactic tag.
A set (word, lemma, tag) of the annotated text matches an item:
For example, the item "be/Vai" will match every occurence of the auxiliary "be" in the indicative tense: is/be/Vaid, "are", "was", ....
The item "Ac" matches all the occurences of a comparative adjective.
A pattern matches a part of the text if each item of the pattern matches a set (word, lemma, tag) of the text, in the same order.
A pattern substitution rule puts the text matching a given pattern in brackets and indicates how to calculate automatically the recommendations to be given to the pupils from the original text. These rules can be applied using the UNIX command sed s!pattern_to_be_found!pattern_to_substitute!
Example 2: Pattern Substitution Rule
s! \([^ ]*\)/be/Vaid[^]* \([^ ]*\)/\( [^ ]*\)/Vvpd[^ ]*! \[ \1 \2 ]( to \3 / preterite, passive form)!
If we apply this rule to example 1, we obtain:
Example 3: Rule Application
Australia/Australia/Npµ. [ was discovered] ( to discover / preterite, passive form) by/by/S. Dutch/Dutch/Ap. merchants/merchant/Nc.p in/in/S. 1606/NBR/Dk.p
The last rule to be applied will clean the text from the remaining unused lemma tags.
The result for the first example will therefore be:
Australia [was discovered] (to discover / preterite, passive form) by Dutch merchants in 1606.
This example shows one type of exercise that hides the verbs of the text. Other types of exercises with comparative adjectives and prepositions are also proposed. Each language requires specific exercises corresponding to specific substitution rules. We have only developped exercises for the English language.
Once the exercise texte have been automatically generated, they are converted to HTML format and stored on our HTTP server so that the exercises can be properly displayed in a browser, hereby allowing pupils to fill in the gaps and submit their exercise. Teachers can also retreive an exercise associated to the video they selected, check it, modify it, and select only a smaller part of it. This modified version can be uploaded on our http server and processed by a cgi script in order to generate a new HTML version of the modified exercise that will be retrieved and used by pupils. The following picture is a screen snapshot of such an exercise. Once a pupil has finished an exercise, he is supposed to push the button labelled "envoyer". It calls a cgi script that compares the words typed by the pupil with those found in the closed caption text. The results of these comparisons are returned to the pupils in an HTML page. These results should be useful for self-evaluation.
We have presented how the WWW can help foreign language teachers find pedagogical materials for multimedia lessons. Such facilities are necessary to convince teachers to regularly use the net and the WWW in their working activities.
Preparing lessons can be very time consuming. Even though technology will never replace teacher's skills, it can help them in their preparation and therefore save time. We also believe that with such technology, multimedia lessons will be more efficient and more attractive to pupils.
The video searching service should prevent teachers from having to view too many videos before choosing the exact contents adapted to their objectives and to the skills of their pupils. Searching among the large quantity of contents becoming accessible through the WWW should be made easier. We can then expect that more contents will be selected and that pupils will be able to find a content more adapted to their own interests within these selections.
Not all on-line videos have contents dedicated to language teaching purposes. They are often difficult to understand for learners. We have shown how we can use hypermedia technology to help pupils to understand them. The generation process of these more easily understandable videos can be applied to any closed captioned videos that can be streamed on-line. Navigation in the video and access to word definitions being easier, the multimedia lessons will be more efficient. Pupils are less bothered by technology and can concentrate on the viewing and understanding of the video. They can go faster and therefore watch more videos and practice more exercises.
Use of the closed caption text for grammar exercises is a way of associating practice with a more formal knowledge of a language. Viewing videos provides motivation for pupils who can have fun before continuing with more conventional activities. That’s why we thought that applying our automatic generation process of gap-filling exercises seemed particularly interesting.
Obviously, although we carried out many interviews with teachers before starting our work, and we received a lot of support from them for our developments, all these previous remarks are only based on assumptions. Some real experiments are currently being prepared. At the time of writing, we only have presented our prototype to a few teachers. The first feedback we have is extremely encouraging. More experiment results will soon be available and will help us to adapt the designed service to the real needs of teachers. We are convinced that the WWW and associated technology will be used only if the services offered take into account the current activities of teachers and their specific requirements. We are in the first round of a cyclical design process. The future will show us how to continue.
We would like to thank all the members of France Telecom R&D who have helped us to make these developments. Thanks are especially addressed to Nicode Devoldčre, Valery Sky, Jannick Collet and Patrick Auvray.
.
[2] Un environnement de développement pour le TALN, Christine Chardenon, Journée d'étude de l'ATALA 15 Décembre 2001 http://www.atala.org/je/011215/Chardenon.pps
[6] MULTEXT Common Specifications and Notation for Lexicon Encoding and Preliminary Proposal for the Tagsets.
[URL2]: Just as examples: www.abc.com, www.cnn.com
[URL4]: Replay TV, www.replaytv.com
[URL5]: http://www.loc.gov/copyright/title17/ and especially http://www.loc.gov/copyright/title17/chaper01.pdf § 107 about fair use for educational purpose
[URL6]: MULTEXT Common Specifications and Notation for Lexicon Encoding and Preliminary Proposal for the Tagsets
[URL7]: BNC Corpus, http://info.ox.ac.uk/bnc/
[URL8]: SMIL Synchronised Multimedia Integration Language, http://www.w3.org/AudioVideo/
[URL9]: Merriam Webster Dictionary , http://www.m-w.com/book/neteds/ntc10.htm
[URL10]: HOTPOTATOES , http://web.uvic.ca/hrd/halfbaked/
[URL11]: Zybura's Toolbox for Teachers, http://www.zarb.de/internat.htm