The Internet has become a popular and effective communications infrastructure, however connection failures are frequent and may leave the final status of a client-server (customer-vendor) interaction in doubt. This paper presents a new user-level communications protocol, the Web Transaction Protocol (WTP), which allows client-server interactions to commit with ACID semantics. We first discuss related work, then describe browser-based client-server interactions over HTTP and identify critical failure scenarios and necessary recovery actions. The WTP protocol is then described, along with a prototype implementation based on persistent queues (backed by a standard relational database system). We conclude with a preliminary performance analysis and future extensions. The major contribution of this paper is a demonstration that it is possible to provide ACID transactional support for Internet interactions by way of nominal extensions to the user-level communications infrastructure.
Keywords: transaction, atomic commit, persistent queueing, client-server communication
Approximate Word Count: 7250 words
The Internet has become a popular and effective means of allowing consumers to shop for goods and place orders directly with vendors. Consumers expect at least the same degree of reliability that is provided when ordering by telephone from a paper catalog distributed by postal mail. While Internet technology allows for less expensive and possibly more widespread distribution of information about products and services that are available for sale, placing an order over the Internet can result in an uncertain outcome, particularly in fully on-line systems without 24/7 call center support. A major source of difficulty is the frequency of failures within the various components making up the communication path between the consumer's browser and the vendor's order entry application, and the inability of the standard Internet communications software to mask these failures.
When placing an order by telephone there is immediate feedback from the customer service representative. He or she will typically confirm each item as it is being ordered by the customer, and then reconfirm the order when it is complete and the customer has provided payment and shipping information. As the customer service representative collects the order information from the customer, it is entered into the vendor's computer system in order to initiate subsequent order fulfillment. The oral exchange of information during manual data entry is a frequent source of errors. After order entry is complete, the customer is given a confirmation number to use if any future questions or problems arise. If the telephone connection or vendor's computer system fails during the short time between completing the order and receiving a confirmation number, then the customer may need to telephone the customer service representative again in order to determine the final status of the order, however this is usually straightforward for the customer to do.
Shopping over the Internet allows for interactive viewing of catalog data and selection of items to be ordered, as well as interactive entry of shipping and payment information. Browser technology allows catalog data to be presented using a variety of multimedia presentation formats. The customer can examine the specific items in the order at leisure and confirm visually that the order is complete and accurate. Many customers find this process to be much simpler and less prone to error than use of a paper catalog and transmittal of order information via telephone. Once the order is complete, however, there must be a mechanism for the customer to securely and reliably transmit the order to the vendor's order fulfillment computer system. This is usually accomplished by establishing a secure connection between the customer's browser and the order entry application running on the vendor's order fulfillment server, and then asking the customer to reconfirm the order contents and enter billing and shipping information. Once the order has been reconfirmed, the customer is asked to take a specific action, usually clicking a button on the final form, to submit the order. The system responds to successful submission with a confirmation number, as above.
The critical window of failure in this scenario is the time between when the customer clicks the final submission button and when the customer's browser displays the order confirmation number. Although the amount of time involved is short, Internet communication is currently much less reliable than most telephone connections and failures occur more frequently. The highest degree of customer dissatisfaction occurs when there is no clear way to determine on-line whether or not an order has been placed, and telephone service representatives are not available to resolve the problem. Email is a relatively slow and difficult means for many customers to use, and may be ineffective in providing sufficient information for the vendor's service personnel to be able to determine if an order has actually been placed.
The goal of this paper is to present a possible solution to this problem. Our approach is to modify the Internet data transport protocols in a transparent fashion so that the action of confirming the order and receiving the confirmation can execute with transactional semantics [Gray93]. We do this by designing a new protocol, WTP, which is used for reliable Internet communications in much the same way that the https protocol is used for secure Internet communications. This paper presents the WTP protocol, demonstrates that it provides transactional semantics and describes an implementation using Microsoft Internet Explorer (this is for demonstration purposes only, our new protocol is browser independent). The major contribution of this paper is a demonstration that it is possible to provide ACID transactional support for Internet interactions by way of nominal extensions to the user-level communications infrastructure.
This paper is organized as follows. The next section describes related work. The following section describes basic browser-based client-server interactions, standard Internet communications using the http protocol, and the failure scenarios we address. Section 4 describes the semantics and operational behavior of the WTP protocol. Sections 5 and 6 describe an implementation of the WTP protocol using persistent queues, and a possible implementation of persistent queues using a standard relational DBS. We conclude with a brief discussion of performance and summarize ways in which our protocol implementation could be improved.
Early work on communications protocols to support E-commerce focused on atomicity: the ability to insure that user requests either execute in their entirety, or have no effect at all. The Transaction Internet Protocol (TIP) [Lyon98] uses the presumed-abort variant of two-phased commit to insure atomicity of a multi-agent distributed computation. This protocol is designed to replace the diversity of proprietary and standardized variants of two-phased commit that now exist, making implementation of distributed transactions across heterogeneous platforms unnecessarily complex [Evan98]. By using a novel "two-pipe" architecture, existing communications protocols (e.g. http) can be used without modification for inter-agent communication during transaction processing. Agents use the TIP protocol to join the transaction during execution, and again at end of transaction to atomically commit (or abort) the transaction. This is the only transactional support provided however.
Transaction atomicity (reliability) is of particular concern when transactions involve transmission of electronic money [Tyga96] [Camp97]. In order to guarantee that money is neither created nor destroyed during an E-commerce transaction, it must be possible to insure that not only is the execution atomic, but that all four of the ACID transactional properties hold. Other critical issues include privacy and security. Both papers provide a brief survey of systems in use at the time of publication, and note that most were deficient in all three areas. In addition to money atomicity, Tygar identifies goods atomicity and certified delivery as essential services to support E-Commerce [Tyga98]. The NetBill and cryptographic postage indicia systems, which he co-designed, use a centralized server and secure hardware (co-processors), respectively, to insure atomicity of client-server transactions, as well as providing other essential transactional services.
The CheeTah system is based on a new theory of transactional interaction that requires neither a centralized monitor nor a static configuration of distributed components [Pard00]. Integrated concurrency control and reliability are provided using an open nested model of transaction execution that guarantees serializable and both globally and locally recoverable execution. Transaction atomicity is provided using a lock manager and undo operations for individual operations. The system as a whole behaves as an interacting collection of transaction monitors with an arbitrary topology. All application components are implemented using a new collection of Java API's (which in turn implement the concurrency control and recovery infrastructure and use local JDBC access for logging). Benchmark measurements indicate that CheeTah based implementations have higher throughput than those using a commercial TP-Monitor, and are comparable to those using a commercial database system.
Lomet addresses transaction reliability within a greatly simplified topology consisting of a single server (with a local database system) supporting multiple application clients [Lome98]. The techniques presented in this paper allow for transparent recovery of both the server and application clients through integrated logging of both messages and server database updates. The logging algorithms are carefully designed to minimize the I/O and synchronization overhead required and client (application) recovery actions are closely integrated with server recovery actions. Although performance is expected to be better than that of an equivalent system based on persistent queues, both the message transport and database system code must be modified to support this strategy.
Many of today's Internet applications are part of the World Wide Web (WWW). In general, Web data is stored on servers and is accessed using Web browsers (e.g. Netscape Navigator or Microsoft Explorer). The basic functions of a Web browser are to gather information from the user, format the information into a service request, transmit the request to the appropriate server, receive the server's response, and display the response contents to the user using an appropriate screen layout. Web resources (data) are identified using an URL (Uniform Resource Locator). The URL is made up of the following components [Bern94]: the name of the scheme (protocol) used to access the data, e.g. http; the fully qualified domain name or dotted-decimal IP address of the host on which the data is located; the port number to connect to (if different from the default value); the location of the file containing the data; the name of the file; and a file extension identifying the type of information contained in the file (e.g. html, text or XML).
The original HTTP protocol (1.0) uses a simple request-reply communication paradigm [HTTP]. The client first establishes a reliable TCP connection with the server and then a single HTTP request is transmitted to the server. The server responds and then closes the TCP connection. The connection oriented TCP protocol is thus being used in a connectionless mode. Newer versions of the HTTP protocol attempt to re-use TCP connections in order to increase efficiency, however the logical behavior of these more complex communications remains unchanged.
The request sent by the client to the server contains the method being requested, the URL of the data (or other resource) being accessed, the version of the protocol being used, request modifiers, client information and the request body content. The three most commonly used methods are GET (to return the resource being requested), HEAD (to return the resource metadata only) and POST (to indicate form data is included in the request immediately after the URL). The server response contains a status line (with the protocol version and a status code), server information, entity meta-information and body content. Although logically each HTTP request returns a page (file) of data, possibly with embedded URL that are used to fetch additional resources during display, the page itself may either be explicitly stored or dynamically generated during request processing (e.g. using servelets or a CGI program). The format of the HTTP response is the same in either case.
Transactions are the fundamental unit of work in reliable systems [Gray93]. Transactions have ACID semantics, where ACID is an acronym standing for atomicity, consistency, isolation and durability. Under atomicity, a transaction either executes to completion and commits, or aborts and has no effect on either the shared system state or other transactions. Consistent transactions transform the shared state in the system from one consistent state to another, where a consistent state is one that satisfies all integrity constraints. Subsystems that enforce transaction semantics assume that all transactions are consistent and do not actively enforce this property. Isolated transactions do not make their changes to the system state visible to other transactions until after they successfully commit. Any changes made by durable transactions are preserved by the system, regardless of failures that might occur after the transaction commits. Transactions that execute with the ACID properties satisfy a standard of reliability and consistency sufficient for accounting purposes, as well as most other applications requiring reliable execution.
Within the context of Internet transactions, as addressed in this paper, the customer action of placing an order and receiving a confirmation is the important unit of work. During the period of time that the customer is selecting items to order, neither the vendor nor the customer has agreed to the sale and there are sufficient opportunities to exchange additional information in order to clarify and possibly correct the order contents and billing information. Once the customer submits the order, however, it should be possible for the system to guarantee that the order is placed exactly once or not at all (atomicity), that the order as placed by the user is correct (consistency), that no other customers see the effects of this order until it successfully commits (isolation), and that the order will be processed by the vendor's order fulfillment system and a confirmation returned to the customer regardless of any transient failures that might occur (durability). Furthermore, the customer should not need to take any special steps to determine whether or not the order was successfully placed, either during normal operation or in the presence of failures.
Consistency is provided by allowing the user to review the order for correctness before submission and allowing the backend database system that supports the vendor's order fulfillment system to check the order against its collection of integrity constraints during processing. If a constraint violation is detected, the order fulfillment system will return a failure message rather than a confirmation number. The backend database system also provides isolation among concurrent customer orders. The WTP protocol is thus only responsible for guaranteeing atomicity and durability of the customer's order (client request).
Consider the simple situation where a user enters a collection of information into a form, submits the form for processing, and then waits for a response from the server indicating that the request was successfully processed, as in the example outlined above. The major steps of this processing are as follows:
In this scenario, client failures can occur (1) before the request is sent, (2) after the request is sent and before the response is displayed, and (3) after the response is displayed. Server failures can occur (4) before the request is received, (5) after the request is received and before the response is sent, and (6) after the response has been sent. Furthermore, (7) each of the two messages can be lost in transit (due to client/server failures or a temporary loss of connectivity, the TCP protocol will automatically recover from other types of message delivery failures). The WTP protocol described in this paper allows automatic recovery from all of these types of failures. This is accomplished by making message transmission between the client and server atomic and durable (i.e. by guaranteeing that each message sent is received and processed exactly once) and by integrating automatic recovery mechanisms into the client and server software.
When a client or server failure occurs, the first step in recovery is to restart the failed component. Once the component is operational and its local state has been restored to a consistent state (using mechanisms outside the scope of this paper), then any pending client requests must be resolved. If the client failed before the request was submitted (case 1) or after the response was displayed to the customer (case 2), then no recovery actions are necessary. If the client failed after submitting the request and before receiving/displaying the response (case 3), then it should wait until the server completes processing the request and sends its response, and then display the response to complete processing. If the client failed after receiving the response but before displaying it, then client recovery actions should restore the incoming message from the server along with the other client state so that the message can be displayed once normal operation resumes. If the server failed before receiving the client's message, then this message will be delivered and processed after normal operation resumes (case 4). If the server failed during request processing, then the server recovery actions must restore the incoming message from the client along with the other server state (case 5). If the server failed after sending its response (case 6), then no additional recovery is necessary. If message transmission is atomic and durable, then no messages are lost in transit and no failures of type 7 occur (assuming connectivity is eventually restored).
The Web Transaction Protocol logically behaves as a sub-layer between the HTTP and TCP protocols. HTTP messages normally are transported over individual TCP connections, as described above. When the WTP protocol is used, the HTTP messages are encapsulated within WTP packets, which are in turn sent out over a TCP connection to the server. A single TCP connection is used throughout client-server interaction. TCP guarantees reliable, in order delivery unless there is a loss of connectivity, in which case an error indication is returned to the peers on both ends of the connection, triggering recovery actions. WTP packets have a character string format. The body of the message is assumed to be in character string format, with any spaces replaced with "+" characters, as in the HTTP protocol. The WTP packet header consists of key-value pairs. All headers contain a function key, along with additional keys, depending upon the function. The supported function parameters are:
| enqueueRequest | pass a request to the input queue |
| commitEnqueueRequest | commit the transaction which passes the message to the input queue. |
| dequeueResponse | remove the response from the output queue |
| commitDequeueResponse | commit the transaction which removes the response from the output queue |
| readRequest | read the request from the input queue (note this function is not used by the client) |
| readResponse | read the response from the output queue |
| lastRequest | return the clientTID of the last request sent by this client |
| lastResponse | return the clientTID of the last response received by this client |
Other keys that might be included in a WTP header are: clientID (unique ID of the client that submitted the request); clientTID (client's ID number for the transaction) priority (priority of the request); transID (unique ID of the transaction in the server); result (indicator of whether or not an action was successful, this is generally returned to the client from the server), numTries (number of times the server has attempted to execute a request); avail (also returned in response to "readRequest", an indicator of whether or not the request is available for execution by the server).
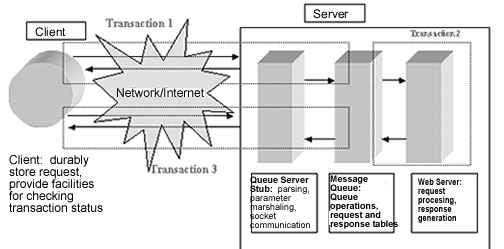
In order to implement WTP, a supporting structure is needed to supply the reliability and recovery characteristics specified by WTP. These characteristics require a means of providing reliable communication and determining the status of transactions. Therefore, modifications to the system architecture must be made to produce a structure that can support transactional semantics. The protocol is implemented as a plug-in type browser extension on the client side, or pluggable protocol. This component works in conjunction with an asynchronous persistent queueing system on the server side. The system uses the queue in order to provide more robust communication between client and server, based upon the techniques outlined in [Bern97]. The queueing system also enables client recovery and discovery of transaction status in case of failure. The material presented in this section is a condensed version of [Wong00].
The bulk of the queue components reside upon the server machine. They can alternatively be placed upon the same network as a server farm. Placement of queue component upon a network would enable use of the queue for scheduling purposes, each server pulling its job from the queue in turn.
Access to the server's portion of the message queue is available via an API defined in an MQServer object. The queue has different sets of entry points for the server and for clients. Server methods are called directly as library functions by the server. Client-oriented methods of the MQServer object are called by a server-side stub after unmarshaling the client's message and parameters.
The queue is used on the client and server sides of the WTP architecture in different ways. It is used on the client side to support presentation services as well as recovery. On the server side, it is used to securely store requests and responses when they are not being executed by the server. The next section describes the way in which the supporting structure of the queue is applied to the client side of the WTP architecture.
The client portion of the queue resides upon the client machine. It consists of the WTP protocol implementation, which performs services such as parsing the input parameters, connecting to the server, logging the client's request in the client log, marshaling the parameters, and sending the request to the server [Bern97]. The client module also pulls the request off the server and formats the results for display to the user. If the client's attempt to dequeue the response fails, then the client can ascertain the status of the request by querying its own log and sending additional messages to query the server's tables. The WTP protocol implementation uses methods available through the queueing system to execute the queueing operations, access the client database, and perform recovery.
The WTP protocol is implemented using a pluggable protocol for Internet Explorer [Espo99]. There are two different ways to create a pluggable protocol for Internet Explorer described in MSDN Online's Asynchronous Pluggable Protocols Overview [Micrxx]. One way is to create a com object which must implement a set of interfaces in the Asynchronous Pluggable Protocols API. The second is to create an application and link it with the URL protocol in the registry.
In the first method of creating a pluggable protocol, the protocol is defined in a com object by mapping the protocol's functionality to IInternetProtocol family of classes. The new com object must be registered under HKEY_CLASSES_ROOT\ Protocols\ Handler\ <protocol>. When the protocol is used, the browser searches for the proper class and calls a set series of methods in a set order. What these methods do depends upon the protocol implementation. The benefits to this approach are that extra functionality can be added to the browser's normal mode of operation, and it can be particularly useful for data filtering purposes. The drawbacks are that it is somewhat restrictive, since most of the interfaces must be implemented, and will be called in a set order.
The second method of creating a pluggable protocol is to register an application to a URL protocol. With this method, any time the protocol is called by the browser, the browser will search for an application registered under the protocol name. The browser then runs the application (which implements the protocol) behind the scenes, passing in any additional information in the url. In the prototype implementation of WTP, the url "WTP:" is used to trigger the application, and an html form is employed to pass in necessary parameters to the application. The application processes the request, and displays its result in the browser [Spen00]. The pluggable protocol provides a means of implementing and distributing WTP as a new protocol for use in place of http. Another aspect of the browser plug-in is the input and output requirements of the WTP application, which is discussed in the next section.
Like http, WTP requires certain information for operation, such as the location of the server, which information to request, etc [Espo99]. Similar to http, the necessary information is passed to WTP in the url. This section describes the nature and format of the initialization data required by WTP and discusses how this information is passed to the WTP protocol implementation. It also discusses how the server responses are passed through the WTP protocol implementation and presented to the user.
The WTP protocol implementation currently expects to be passed a string as an input parameter. This string is the url that starts the operation of WTP and should begin with "WTP:". The protocol implementation expects the string to consist entirely of key-value pairs which are formatted in the same way that form key-value pairs are passed, i.e.: key1=value1&key2=value2, etc. In the current implementation, the string must contain the keys ipAddress, clientID, clientTID, priority, request. In a production implementation, the clientID and clientTID should be derived implicitly instead of passed in explicitly. The clientTID (Transaction ID numbers should be unique within the scope of that particular client) is made explicit here for testing purposes. In the course of normal use, this number should be a unique number derived after checking previous transaction records in the client log. The priority value should normally be specified by the designer of the initial page leading to the startup of the WTP protocol but not visible to the end user. The request is a character string, and depending on the size of the storage in the queue, can be anything from a single character to an http request.
Clicking the submit button submits the form. The form action is defined as "WTP:=", and the form key-value pairs are automatically gathered into an input string of the proper format. The resulting string passed into the WTP protocol application will be:
"WTP:=form1&ipAddress=<ip_address>&clientID=<client_ID>&clientTID= <client_TID>&priority=<priority>&request=<Enter request here>".
The application will then parse these parameters, create an MQclient object, and submit the request to the server.
The system is currently designed to handle short character strings for both request and response, as opposed to entire html pages. This is for purposes of testing and clarity, as it is much easier to test and annotate the system's behavior using short strings.
WTP expects an input string containing specific key-value pairs that allow it to contact the server with the client's request. It is capable of presenting the results to the user in a number of different ways. Although a pre-defined web page is used to display short response and recovery strings in this implementation, in practice the response would probably contain an entire web page generated by the server that would then be displayed to the user. The information displayed to the user is determined by the status of the transaction and whether or not a previous failure has resulted in the need for recovery.
The queue implementation uses a database system to provide reliable storage of data [Gray93]. This section describes the way in which the client and server sides of the queue system use database support, as well as the design of the database tables. The material presented in this section is a condensed version of reference [Wong00], and is based on the techniques outlined in references [Gray93] and [Bern97].
MS SQL Server is used as the database system for storing the queue information. SQL Server allows for the creation of stored procedures (see Appendix C), which provide performance benefits to the system because they are precompiled rather than parsed at run time. Most of the queue operations are implemented using stored procedures.
A. Server Side Database -The database storage of the queue is implemented in four tables: 1. RequestQueue: This table is used to hold client requests, which are removed by servers as they become available.
| TransID | ClientID | ClientTransID | Request | Available | NumTries | Priorit |
2. FailedRequestLog: Records are placed in this table in the event that the request is attempted and fails to be executed successfully a certain number of times. This table can later be examined by a DBA for security/maintenance purposes.
| TransID | ClientID | ClientTransID | Request |
3. ClientLog: This table enables the client to discover the status of its last submitted request in the event of client failure.
| ClientID | LastReq | LastResp |
4. ResponseQueue: This table is used to hold server responses to client requests, to be removed by the clients who issued the requests.
| TransID | ClientID | ClientTransID | Response |
Table Fields:
B. Client Side Database: There is an additional database on the client side, which the client uses to store its own queue information. It contains only one table:
1. clientLog: This table is used to hold the client's information to be used for recovery purposes.
| ClientID | clientTID | request | enqueued | dequeued | Response |
Field Values:
For correct system operation, the database must be used to provide partial but not complete transactional semantics for the queue [Gray93]. The database system supplies the concurrency control that is necessary for the server-side queue component. However, it is also important to keep a permanent record of attempts to execute requests from the requestQueue which did not complete successfully. Although this violates the property of atomicity, it is essential in order to prevent repeated system crashes caused by severely malformed requests.
Use of a database for storage of the queue data on the server side allows the client (via use of the stub) and the web server(s) (through use of the MQServer methods) to access the queue concurrently without data corruption [Gray93]. The client side database is not as pivotal to the operation of WTP. If there is only one client per machine and no need for concurrency control, the data can easily be stored in a flat file. Alternatively, as not all browsers allow file system access, the data can also be stored as a cookie on the client machine. Since a cookie is simply a line of text in a specially formatted file, it would be sufficient for storing the persistent data needed for purposes of client recovery. Although a flat file or cookie would be less reliable, it would consume much less space than a database. It would also be much less expensive from the client's point of view, both monetarily and in terms of performance.
In many cases, the queue's use of the database's transactional properties supplies the system with increased fault tolerance. However, it also makes the web server vulnerable to any request that is so malformed that it will consistently cause a failure of the transaction that the server uses to remove the request from the input queue. If the request is malformed enough to cause the web server to fail, then this transaction will roll back, and the request will be replaced in the RequestQueue. This will continue to occur, causing the web server to crash repeatedly. The NumTries field in the RequestQueue is specifically included in the table for the prevention of this situation. The field is incremented every time a server attempts to execute the request [Gray93]. If the request is fatally flawed and the server is forced to abort this transaction after some number of times, then the request is removed from the request table and moved to the failedRequestLog table. This violates the atomicity of the queue resource manager, since even if a transaction rolls back, an indication of this will have been durably saved. However, it performs the important function of keeping a fatally flawed request from looping forever.
There are several commercial message queueing middleware products available such as Microsoft's MSMQ that could be integrated into an implementation of WTP. In [Hous98], Peter Houston discusses the reasons for and benefits of using a middleware message queueing product for communication in distributed transaction systems. Use of a messaging queue can alleviate problems with synchronization and network reliability by providing what Houston describes as "reliable, asynchronous, and loosely coupled communication services". Integration of such a queueing product into an implementation of WTP would significantly simplify the implementation process.
Microsoft's messaging queue product is Microsoft Message Queue (MSMQ). While the earlier version of MSMQ required the use of an MS SQL Server database, the newer version utilizes a proprietary database specific to the queue. The queue can be either transactional or non-transactional, communication can be synchronous or asynchronous, and clients can be either dependent or independent. Messages passed can be any type of data, and can be used to implement store and forward communication. The product also comes accompanied by utilities regarding routing, security, and prioritization. The API offers a wide range of entry points which allow the user to create, locate, send, and retrieve messages, as well as additional functionality.
The material presented in this section is a condensed version of [Wong00].
With most systems, there are performance costs involved in transactional support [Bern97]. In the absence of failure, most of the overhead in WTP is due to the use of connection-oriented communication and the database system. However, the overhead imposed by these elements is reduced by using the connections efficiently and by using stored procedures for the database.
Connection-oriented communication carries the overhead associated with connection establishment and TCP protocol operation [Come95]. However, the benefits of TCP's connection oriented nature guarantee that either messages will be delivered completely and in order, or not at all, in which case the system will be notified that the connection has been broken. These qualities are necessary to maintain the transactional qualities of the system and to protect the data. The connection is used as efficiently as possible by maintaining the connection for the duration of the client's execution.
Another major source of overhead in the WTP system is the use of databases. The performance costs on the server side are necessary, since the database is used to provide much of the queue's transactional and concurrency support. It is an essential component of the server portion of the WTP implementation. On the other hand, replacement of database support with a flat file in the client component would result in a slight decrease of reliability and tremendous profits in client performance and ownership costs.
If no failures occur, then the WTP system must access the database on the client side several times: once at startup to check to see if recovery is needed, twice for enqueueing the request, and twice for dequeueing the response. It must also take the time to establish a connection with the server portion of the queue. The server side must access the database in order to dequeue the request and enqueue the response.
If recovery is required, more database accesses are necessary in order to discover the status of the transaction. The additional amount of work needed is dependent upon the status of the transaction. If a request was not successfully enqueued, then this can be discovered immediately at the time the clientLog is checked. If the request was successfully enqueued but not dequeued, then more checking must be performed. In this case, the client must first check the server's request queue for the missing request. If the request in not in the request queue, then the client must check the response queue. If the request is in neither, and is not in the failed request log, then by the process of elimination, the client must assume that the request is in the process of being executed by the server. The client must then repeat its attempts to dequeue the response from the server.
The current method of conducting web transactions using http does not provide enough reliability. A system is needed which can provide reliability, recovery, and can notify the user of the transaction's status in the absence of successful completion. WTP provides a good alternative to http in the use of web transactions. Queues can be used to add robustness to many distributed systems, and allows the WTP system to communicate reliably and perform recovery.
The current implementation of WTP as developed for this project includes some features designed to support testing and demonstration, such as the client-side database, message size limitations, and presentation methods. The system would be much easier to deploy as a plug-in if a flat file or cookie were used for client-side storage. The message sizes should be enlarged, and administration tools could be developed for tuning message sizes and database settings. The response message size should be expanded to hold a response web page, rather than a response string.
The current system is written as a pluggable protocol for Internet Explorer, and based upon a MS SQL Server database. Future work could include porting the client-side code to other platforms and browser types. Since the code is written in Java, the only changes necessary should be protocol triggering and display methods and replacement of the database with a file. Although the server side code is also written in Java, it uses MS-specific ADO to access the database. Because connection with the database is based upon an ODBC data source user-defined DSN, the system is not bound to MS SQL Server, and any database that allows stored procedures could be used in its place. On the other hand, since the rest of the code is written in Java, the database access methods could be changed to JDBC, thereby improving platform portability.
[Bern94] Berners-Lee, T., Masinter, L., and M. McCahill, "Uniform Resource Locators (URL)", RFC 1738, December 1994.
[HTTP] HTTP: Hypertext Transfer Protocol, W3.org protocol overview, 5/17/01, http://www.w3.org/Protocols/Overview.htm
[Bern97] Bernstein, P., A. Newcomer, Principles of Transaction Processing. Morgan Kaufmann, Publishers, Inc., San Mateo, CA, 1997.
[Wong00] Wong, Jennifer, "Reliable Internet Transactions: Utilizing a Browser Extension and Server-side Persistent Queue for Transactional Client-Server Communication", MS Report, SFSU Department of Computer Science Technical Report SFSU-CS-TR-00.15, 12/07/2000.
[Micrxx] Microsoft Corporation. "Asynchronous Pluggable Protocols Overview", in MSDN online Web Workshop. Available via http://msdn.microsoft.com/workshop/networking/pluggable/pluggable.asp
[Spen00] Spencer, Steven. "Java tip 66: Control browsers from your Java application". Available as of July 2000 via http://www.javaworld.com/javaworld/javatips/jw-javatip66.html
[Espo99] Esposito, Dino. January 1999. "Cutting Edge: Pluggable Protocols" in Microsoft Internet Developer. Available via MSDN Library July 2000
[Gray93] Gray, J., Reuter, A. 1993. Transaction Processing: Concepts and Techniques. Morgan Kaufmann Publishers, Inc., San Mateo, CA.
[Hous98] Houston, Peter. March 1998. "Building Distributed Applications with Message Queuing Middleware" in MSDN Library July 2000 edition.
[Come95] Comer, Douglas E. Internetworking with TCP/IP, Volume 1, Principles, Protocols and Architecture. Prentice Hall, Upper Saddle River, NJ, 1995.
[Lyon98] J. Lyon, K. Evans, J. Klein, "Transaction Internet Protocol Version 3.0", Internet RFC 2371, July 1998.
[Evan98] Evans, K., J. Klein, "Transaction Internet Protocol-Requirements and Supplemental Information" Internet RFC 2372, July 1998.
[Tyga96] J.D. Tygar, "Atomicity in electronic commerce", Proceedings of the fifteenth annual ACM symposium on Principles of distributed computing, 1996, Pages 8 - 26
[Camp97] L. Jean Camp and Marvin Sirbu, "Critical Issues in Internet Commerce", IEEE Communications Magazine, May 1997.
[Tyga98] J.D. Tygar, "Atomicity in electronic commerce", netWorker 2, 2 (Apr. 1998), Pages 32 - 43
[Pard00] Guy Pardon, Gustavo Alonso, "CheeTah: a Lightweight Transaction Server for Plug-and-Play Internet Data Management", VLDB 2000: 210-219
[Lome98] David Lomet and Gerhard Weikum, "Efficient transparent application recovery in client-server information systems", Proceedings of ACM SIGMOD International Conference on Management of data, 1998, Pages 460 - 471
Ms. Jennifer Wong is currently a software engineer at Covalent Technologies. The work presented in this paper was done while she was completing a M.S. Project at San Francisco State University under the direction of the second author.
Professor Marguerite Murphy has been on the faculty at San Francisco State University since 1985, when she completed her PhD in Computer Science from U.C. Berkeley. Her research interests include Database Systems, Computer Networks and Multimedia Systems (http://mictlan.sfsu.edu/~murphy).