Querying Linked XML Document Networks in the Web
Wolfgang May
Institut für Informatik, Universität Freiburg, Germany
Abstract
The W3C XML Linking Language (XLink) provides a powerful means for
interlinking XML documents all over the world. From the database
(and in general, querying) point of view, elements with linking
semantics as specified by XLink can be seen as embedded views in an
XML instance. Compared with classical databases, i.e., SQL and
relational data, the situation of having links inside the
data is new, raising new aspects for query languages: for using such
documents, strategies how to handle links are required. There is not
yet an official proposal on the interaction of interlinked XML
documents using the XLink language and navigation/querying. We
investigate a model where interlinked documents are regarded as
virtual XML subtrees, i.e., XML views. Several
strategies are presented how to handle such subtrees, concerning the
timepoint when the link is evaluated, and the evaluation and caching
strategies. The evaluation strategies are influenced by
capabilities of the linked XML servers. So far, the approach is
independent from the actual querying language. The approach is under
implementation as an extension of LoPiX
[LoPiX], a
web-aware system for XML data manipulation.
1. Introduction
XML has been designed and accepted as the framework for
semi-structured data where it plays the same role as the relational
model for classical databases. As a data format tailored to the use
in the Web, XML data is not required to be self-contained on an
individual server, but may include links to XML data on other
servers. The XML linking semantics is specified in the XML
Linking Language (XLink) [XLink] by providing special tags
in the xlink: namespace that tell an application that an
element is equipped with link semantics. The remote servers may be
autonomous, i.e., they are not aware of being referenced by
other documents.
In general, links specified by using XLink express whatever
relationships between resources. We see our work from the database
point of view, where information is distributed over several XML
instances: we restrict the considerations to the querying
aspect, i.e., to links that specify an XML tree that is intended to be
used at the position of the link element. Although, many of the
considerations carry over to the document area, and to resources
described by XML in general. In our context, a link element in an XML
document is primarily an embedded view definition, given as a query
against another document where suitable information can be found.
Thus, this view has to be evaluated when the link element is actually
traversed in a query. Working with such documents containing links to
remote sources raises several questions:
- the size of the complete linked documents may be tremendous
(since they may again contain links to further documents), even if
perhaps only a small excerpt is needed for an application.
- if a link element is found, is it preferable to ``evaluate''
it first, ``materializing'' the answer instead of retaining the
link, or is it preferable to regard the link as a virtual
tree fragment that is queried on-demand? In both cases,
the practicability heavily depends on the services provided by the
remote data source. In the virtual case, additional strategies may
be used based on metadata information of the remote source to check
if the source is relevant for answering the actual query
- it is desirable that links are transparent, i.e., queries
behave as if the target of the link is declaratively accessible
via the link element.
In the presence of internet-wide distributed documents provided
by servers that implement different access policies and
server-side/client-side querying mechanisms, efficient evaluation of
queries requires a well-defined and well-specified cooperation between
the involved components.
The paper is organized as follows: Since we do not assume that
everybody is familiar with the XLink specification, we first review
the semantics of links as given in [XLink], also introducing a running
example. Section 3 analyzes the correspondences between links and the
view concept and investigates navigation along links from the point of
view of the data model. The distribution aspect of evaluating queries
on the local server or on remote servers is introduced in Section 4,
complemented by considerations on prefetching and caching of data in
Section 5. We systematically identify characteristic parameters for
specifying the handling of links and relate them to the service
functionality provided by remote sources in Section 6. An
experimental environment is described in Section 7. Section 8
concludes the paper.
2. XML Notions
2.1 Querying XML
Example 1
Consider the following excerpt of the Mondial database
[Mondial] for illustrations.
<!ELEMENT mondial (country+, organization+, ...)>
<!ELEMENT country (name, city+, ...)>
<!ATTLIST country car_code ID #REQUIRED
capital IDREFS #REQUIRED>
<!ELEMENT name (#PCDATA)>
<!ELEMENT city EMPTY>
<!ATTLIST city id ID #REQUIRED
name CDATA #REQUIRED>
<!ELEMENT organization (name, members*)>
<!ATTLIST organization abbrev ID #REQUIRED
seat IDREF #IMPLIED>
<!ELEMENT members EMPTY>
<!ATTLIST members type CDATA #REQUIRED
country IDREFS #REQUIRED>
<country car_code=``B'' capital=``cty-B-Brussels''>
<name> Belgium</name>
<city id=``cty-B-Brussels'' name=``Brussels''/>
</country>
<organization abbrev=``EU'' seat=``cty-B-Brussels''>
<name> European Union</name>
<members type=``member'' country=``A B D E F ...''/>
</organization>
XPath [XPath] is the common language for addressing node sets in XML
documents; we assume that the reader is familiar with XPath. It
provides the base for most XML querying languages that extend it with
their special constructs (e.g., functional style commands and
variables in XSLT [XSLT], and SQL/OQL style (e.g., joins) in
Quilt/XQuery [DFF+99, XQuery]).
The core XML/XPath concept already provides unidirectional
intra-document references by ID/IDREF/IDREFS attributes.
Example 2
The following query is used throughout the paper for illustrating
dereferencing:
``Select all names of cities that are seats of an organization and
the capital of one of its members.''
XPath uses the id(...) function for dereferencing:
id(//organization[id(./@seat) =
id(id(./members/@country)/@capital)]/@seat)/@name
yields the names of the above-mentioned cities.
The XQuery proposal [XQuery] (which is based on Quilt
[CRF00]) is the W3C recommendation for querying XML documents. Its
querying fragment embeds XPath syntax into higher-level constructs
(similar to SQL/OQL). Although, already the dereferencing
functionality of XPath is augmented in Quilt/XQuery with a
``=>'' operator for explicit dereferencing. An additional name
test (added by XQuery wrt. Quilt) specifies the expected name of
the target element.
Example 3
In XQuery, the above expression is written as
//organization[@seat=>city = members/@country=>country/@capital=>city]
/@seat=>city/@name .
Example 4
The complete query given above can be stated in
XQuery as follows (returning the organisation's abbreviation and the
city's name). We assume that the city's name is unique to have a
simpler criterion later when using distributed sources:
FOR $org IN //organization,
$abbrev IN $org/@abbrev,
$seatname IN $org/@seat/@name,
$capname IN $org/members/@country/@capital/@name
WHERE $capname = $seatname
RETURN <result org = {$abbrev} city = {$seatname}/>
Here the FOR clause defines variables that are bound to the
elements of the result set of XPath expressions, yielding a list of
variable bindings. The WHERE clause -- similar to SQL/OQL --
states additional conditions which tuples of variable bindings are
used for generating a result element for each variable binding
in the RETURN clause.
2.2 XPointer and XLink
XPointer
XPointer [XPtr] is a specialized extension of XPath for selecting
parts of XML documents -- which are not necessarily sets of nodes. The
XPointer concept combines the URL document addressing mechanism with
an extension of the XPath mechanism for addressing fragments of the
document. XPointer ``hyperlink'' addresses are of the form
url#ext-xpath-expr. Thus, everybody can
define links from his XML documents to any other XML source. For this
work, we restrict ourselves to standard XPath expressions as pointers,
i.e., our XPointers are of the form
url#xpath-expr. E.g., the following
XPointer addresses the country element that has a
car_code attribute with value ``B'' in the document with the
url www.ourserver.de/Mondial/mondial.xml:
www.ourserver.de/Mondial/mondial.xml
#descendant::country[@car_code=``B'']
XML Linking Language (XLink)
XPointers are used in the XML Linking Language (XLink)
[XLink] for expressing links between XML documents. Arbitrary
elements can be declared to have link semantics by equipping them with
an xlink:type attribute and suitable additional attributes
and subelements from the xlink: namespace. These specify the
behavior of a link, i.e., its activating event and the
triggered action. Whereas the HTML behavior is simply ``browse this
document'', the XLink language allows for more sophisticated
activities (e.g., not to delay the behavior until the link is
activated by a user, but evaluate it immediately when the document is
parsed). When links are used for querying XML document
networks, this functionality has to be extended (as we will do in the
subsequent sections). First, we give an overview of the notions
defined by the XLink language:
The xlink:type attribute selects between four basic types of
linking semantics:
- simple: roughly, the semantics known from
< A href=``...''>,
- extended: the same, allowing for multiple targets,
- locator: elements with an
xlink:type=``locator'' attribute are used for specifying
targets that are then used by extended link elements,
- arc: elements with an xlink:type=``arc''
attribute are used for defining bidirectional links between a set of
locator elements.
In most cases, the information that some element type is equipped with
link semantics is given in the DTD. Here, attributes from the
xlink: namespace are declared and some of them are assigned
with a fixed value:
<!ELEMENT linkelement (contentsmodel)>
<!-- Dependent on the xlink:type, some conditions on
contentsmodel apply. -->
<!ATT LIST linkelement
xlink:type (simple|extended|locator|arc) #FIXED ``...''
xlink:href CDATA #REQUIRED
xlink:actuate (auto|user) #IMPLIED
xlink:show (new|parsed|replace) #IMPLIED
xlink:role CDATA #IMPLIED
xlink:title CDATA #IMPLIED>
where linkelement is any element type of the application to be
augmented with link semantics
The xlink: attributes have the following semantics:
- xlink:href: selects a target of the individual
instance (it ``is'' the link).
- xlink:actuate: defines the event on which the
link is activated (when browsing).
- xlink:show: specifies what happens if the link
is activated (when browsing).
- xlink:role and xlink:title: application specific.
In the following, links of the types provided by XLink are introduced
for a ``distributed'' version of Mondial where all countries, all
cities of a country, all organizations, and all memberships are stored
in separate files:
- mondial-countries.xml (all countries)
- mondial-cities-car-code.xml (the cities for each country)
- mondial-organizations.xml (all organizations)
- mondial-memberships.xml (relates countries and organizations)
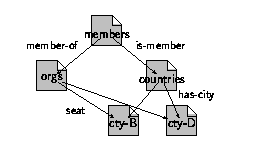
Simple Links
A simple link is similar to the HTML < A href=``...''>
construct.
Example 5
The @seat attribute of organizations is replaced by a seat
subelement which is a simple link:
<!ELEMENT organization (... seat ...)>
<!ELEMENT seat EMPTY>
<!ATTLIST seat xlink:type (simple|extended|locator|arc) #FIXED ``simple''
xlink:href CDATA #REQUIRED >
An excerpt of the XML document mondial-organizations.xml
looks as follows:
< organization id=``org-eu''>
< seat href=``file:cities-B.xml#//city[@name='Brussels']''/>
:
< /organization>
Inline extended Links
Extended links do not have an href attribute, but instead
they contain one or more locator elements, each of
which is a reference of its own.
Example 6
In the distributed Mondial model, every country element has
a simple link element capital, and an extended, multi-target
link element cities that contains locators to all its cities:
<!ELEMENT country (... cities, capital ... )>
<!-- (capital is defined similar to organization/seat) -->
<!ELEMENT cities (city*)>
<!ATTLIST cities xlink:type (simple|extended|locator|arc) #FIXED ``extended'' >
<!ELEMENT city (#PCDATA)>
<!ATTLIST city xlink:type (simple|extended|locator|arc) #FIXED ``locator''
xlink:href CDATA #REQUIRED >
An excerpt of the XML document mondial-countries.xml may look
as follows:
<country car_code=``B''>
<capital href=``file:cities-B.xml#//city[@name='Brussels']''/>
<cities>
<city href=``file:cities-B.xml#//city[@name='Brussels']''>
Brussels</city>
<city href=``file:cities-B.xml#//city[@name='Antwerp']''>
Antwerp</city>
:
</cities>
</country>
Out-of-Line-Links
Out-of-line-links allow to create references not only inside
documents, but also to create XML instances that consist only
of links between other documents. This can be seen as a ``personalized
overlay'' on arbitrary existing (autonomous) sources. Here, the link
is not a directed link to a node, but a relationship (or a set of
relationships) between a set of nodes.
Out-of-line-links consist of locator subelements that
specify potential endpoints of links, and arc elements
that specify the relationships between these endpoints:
<!ELEMENT linkelement (...|locatorelement|arcelement)*>
<!ATTLIST linkelement as above >
<!ELEMENT locatorelement as above >
<!ATTLIST locatorelement as above, including type, href, id >
<!ELEMENT arcelement (contentsmodel)>
<!ATTLIST arcelement xlink:type (simple|extended|locator|arc) #FIXED ``arc''
xlink:from IDREF #REQUIRED
xlink:to IDREF #REQUIRED >
Example 7
For the distributed Mondial database, the memberships of countries in
organizations are stored in mondial-memberships.xml:
<!ELEMENT memberships (country*,organization*,membership*)>
<!ATTLIST memberships xlink:type (simple|extended|locator|arc) #FIXED ``extended'' >
<!ELEMENT country EMPTY>
<!ATTLIST country
xlink:type (simple|extended|locator|arc) #FIXED ``locator''
xlink:href CDATA #REQUIRED
id ID #REQUIRED >
<!ELEMENT organization EMPTY>
<!ATTLIST organization
xlink:type (simple|extended|locator|arc) #FIXED ``locator''
xlink:href CDATA #REQUIRED
id ID #REQUIRED >
<!ELEMENT membership EMPTY>
<!ATTLIST membership
xlink:type (simple|extended|locator|arc) #FIXED ``arc''
xlink:from IDREF #REQUIRED
xlink:to IDREF #REQUIRED
membership_type CDATA #REQUIRED >
The file mondial-memberships.xml consists now of only one
memberships element:
<memberships>
<country id=``B''
xlink:href=``.../countries.xml#//country[@car_code='B']''/>
<country id=``D''
xlink:href=``.../countries.xml#//country[@car_code='D']''/>
<organization id=``org-EU''
xlink:href=``.../organizations.xml#//organization[@abbrev='EU']''/>
<organization id=``org-UN''
xlink:href=``.../organizations.xml#//organization[@abbrev='UN']''/>
<membership
xlink:from=``B'' xlink:to=``org-EU'' membership_type=``member''/>
<membership
xlink:from=``B'' xlink:to=``org-UN'' membership_type=``member''/>
</memberships>
3. Data Models and Queries for Linked Documents
XPointer and XLink specify how to express inter-document links
in XML. There is not yet an official proposal
- how to add link semantics to the actual data model, e.g., the
DOM or the XML Query Data Model [XMLQDM], and
- how to handle links in queries and applications (which
in part depends on the data model, but orthogonally, evaluation
strategies have to be defined).
In this section, we describe two alternative extensions of the data
model with link elements. Evaluation issues, e.g., when and where
links are evaluated, are then investigated in Sections 4-6.
Each link can be seen as a view definition -- possibly recursively
containing further links; in this case, the view may be even infinite
(due to cyclic references). Whereas in SQL, a view or a database link
appears as a table or a database schema that easily fits with the
language syntax and semantics, links as embedded views need
one of the following semantic extensions:
- extending the abstract data model with a linking construct.
In this case, an additional syntactic construct in form of an
an explicit navigation operator is required.
- the abstract data model makes the links transparent, i.e., the
embedded views implicitly become subtrees that can be queried
by standard XPath expressions.
3.1 An Explicit Navigation Operator
The query in the Example 2 uses the XQuery [XQuery]
syntax with the dereferencing operator for IDREF(S),
``=>nodetest''. Similarly, we define the dereferencing
operator ``~>'' for following XPointers in
xlink:href attributes for explicit inter-document
navigation.
Example 8
Consider again the query given above:
The entry point for the query is the document
mondial-memberships.xml, iterating over all
membership elements (e.g., (``B'',``EU'')),
For illustrating in which document the current navigation step is
applied, the namespaces ms: (in
mondial-memberships.xml), org: (in
mondial-organizations.xml), ctry: (in
mondial-countries.xml), and cty: (in
mondial-city-XXX.xml) are used:
FOR $ms IN document(``mondial-memberships.xml'')/ms:memberships/ms:membership,
$org IN $ms/@xlink:to=> ms:organization/@xlink:href~>org:organization,
$abbrev IN $org/@org:abbrev,
$seatname IN $org/org:seat/@xlink:href~>cty:city/@cty:name,
$capname IN $ms/@xlink:from=>ms:country/@xlink:href~>ctry:country/
ctry:capital/@xlink:href~>cty:city/@cty:name,
WHERE $capname = $seatname
RETURN < result org = {$abbrev} city = {$seatname}/>
3.2 Transparent Links
In the above example, an explicit operator for dereferencing links
has been introduced. Another possibility is to regard link elements
to be transparent, i.e., the (abstract) data model should
silently replace link elements of the types xlink:simple
xlink:locator, and xlink:arc by the result sets of
their XPointers (for xlink:type=arc elements, the from
and to attributes are replaced by reference attributes whose
name is the xlink:role type of the corresponding
xlink:locator nodes (if no role is given, the name of the
locator node is taken instead)). Note that these partially ``virtual''
elements must accumulate the attributes and contents of the original
link element (in case it has non-xlink contents) and of the linked
element.
Example 9
With transparent links, the virtually linked XML trees look as follows:
In mondial-memberships.xml, the <country
xlink:type=``locator'' ...> elements are ``instantiated''
with the document(``mondial-countries.xml'')/country elements
resulting from the xlink:href attribute; analogously for the
<organization xlink:type=``locator'' ...> elements.
Similarly, In the <membership xlink:type=``arc''>
elements, the xlink:from attribute is replaced by a
country reference attribute (taking the name of the element
referenced by the xlink:from attribute); analogously for the
xlink:to attribute:
<memberships>
<!-- originally: country xlink:type=``locator''
xlink:href=``.../countries.xml'')#//country[@car_code='B']'' -->
<country id=``B''>
<!-- with attributes and contents of
document(``.../countries.xml'')//country[@car_code='B'] -->
</country>
<!-- originally: organization xlink:type=``locator''
xlink:href=``.../organizations.xml#//organization[@abbrev='EU']'' -->
<organization id=``org-EU''>
<!-- with attributes and contents of
document(``.../organizations.xml'')//organization[@abbrev='EU'] -->
</organization>
<membership
<!-- originally: xlink:from=``B'' xlink:to=``org-EU''
together with types/element names of the referenced locator elements -->
country=``B'' organization=``EU'' membership_type=``member''/>
:
</memberships>
Similarly, in mondial-organizations.xml, the <seat
xlink:type=``simple''> subelements are resolved by the corresponding
document(``mondial-city-XXX.xml'')/city elements:
<organization abbrev=``EU''>
<seat>
<!-- href=``file:cities-B.xml#//city[@name='Brussels']''-->
<!-- attributes and contents of
document(``.../mondial-cities-B.xml'')//city[@name='Brussels'] -->
</seat>
:
</organization>
Analogously, the capital subelements in
mondial-countries.xml are (virtually) resolved.
Then, the query in the virtual linked trees reads in XQuery syntax as
FOR $ms IN document(``mondial-memberships.xml'')/ms:memberships/ms:membership,
$org IN $ms/@ms:organization, <!-- dereferencing the arc element -->
$abbrev IN $org/@org:abbrev,
$seatname IN $org/org:seat/@cty:name, <!-- dereferencing the simple link -->
$capname IN $ms/@ms:country/ctry:capital/@cty:name <!-- dereferencing the simple link -->
WHERE $capname = $seatname
RETURN <result org = {$abbrev} city = {$seatname}/>
Another question is, whether virtual subelements via links should be
considered as descendants. For transparency reasons, it is sometimes
desirable to regard linked XML instances as one. Then, queries are
robust against some restructuring of information servers. On the
other hand, the set of descendants may become arbitrary large.
Additionally, navigation using // has to resolve
(transitively) all links. Thus, it is desirable that the behavior of
a link in this aspect can be defined (cf. Section 6.4).
4. View Evaluation and XML Information Server Cooperation
For evaluating XPath expressions that navigate through link
elements, there are several possibilities, concerning the issues,
when and where the views defined by links are
evaluated. Thus, when links are involved in queries, several
queries/views have to be evaluated, and possibly combined:
- the link url#xpath-exprxl
defines views on different levels:
- wrt. the source document, the whole link is a view (in the
sense of a virtual tree extension),
- and wrt. the referenced url url, the
XPointer portion xpath-exprxl defines a view.
- in general, a query does not need the whole result of the link,
but in course contains a query against it. Thus, the
query which is stated against the source document can be decomposed
as xpath-exprq1/xpath-exprq2
where the result set of xpath-exprq1 contains
the link node and xpath-exprq2 is a
``subquery'' which is evaluated against the view which is defined by
the link.
Thus, for the actual data exchange, several possibilities of
materializing one of the views emerge:
- transfer the whole contents of url and evaluate
xpath-exprxl/xpath-exprq2.
- submit the query xpath-exprxl to the
server at url who materializes and transfers the
result. Then, evaluate xpath-exprq2 against
it.
- submit the query
xpath-exprxl/xpath-exprq2 to
the server at url (see Section 4.2).
In this case, the views defined by the link remain completely
virtual also during evaluation.
When the target of the link resides on a remote server, the actually
applicable strategies depend on the provided services (i.e., whether
the whole XML document is accessible, and/or what queries can be
answered), cf. Section 6.2.
We first sketch two potential evaluation strategies, and then identify
and investigate systematically the parameters for specifying the
behavior of link evaluation.
4.1 Local Evaluation
Current XML querying tools are restricted to evaluate XPath
expressions wrt. the DOM-resident XML tree (which may contain several
documents). When a query is parsed, the documents occurring in
expressions of the form document(url) are added to
the DOM to be evaluated. When handling links, the XPointers giving
the urls and XPath expressions to be evaluated are not contained in
the query, but in the data, thus they are only known at runtime. The
XQuery pattern below describes how an actual query
xpath-exprq1/xpath-exprq2 where
the result set of xpath-exprq1 consists of
link elements can be evaluated in Dynamic SQL or JDBC style:
<!-- evaluate ``FOR X IN xpath-exprq1/xpath-exprq2'' -->
FOR $xlink IN xpath-exprq1
LET $url = string-before(``#'',$xpointer),
$path = string-after(``#'',$xpointer),
$view = document($url)/$path <!-- XPath expression over variables -->
FOR $x IN $view/xpath-exprq2
:
Such queries are not supported by the current querying
languages. Using XQueryX, the above behavior can be implemented in
XSLT [XSLT].
4.2 Remote Evaluation: Keeping the Views Virtual.
When evaluating
xpath-exprq1/xpath-exprq2 as above,
for a link
<foo xlink:type=``simple'' href=``url#xpath-exprxl'' .../>
belonging to the result set of xpath-exprq1,
neither the document at url nor the result set of
url#xpath-exprxl are actually needed,
but only used for evaluating xpath-exprq2}
over the result set. Thus, instead the
rewritten query
xpath-exprxl/xpath-exprq2}
can evaluated against url to answer the original
query. In general, the result will be much smaller than when
evaluating xpath-exprxl -- and the computation
is done at the server which is potentially optimized wrt. its
database.
Example 10
In our example, the source mondial-memberships.xml contains
locator elements like
<country id=``B'' xlink:href=``.../countries.xml#//country[@car_code='B']'' />
that are used when answering the query
(*) $capname IN~~$ms/@xlink:from=>ms:country/@xlink:href~>ctry:country/
ctry:capital/@xlink:href~>cty:city/@cty:name
for the above XPointer, the whole ctry:country element with
car_code=``B'' is returned, and then queried by
ctry:capital/@xlink:href~>cty:city/@cty:name~.
Instead, countries.xml can be queried for
//ctry:country[@ctry:car_code='B']/ctry:capital/@xlink:href~>cty:city/@cty:name
which will in turn query cities-B.xml with
//cty:city[@cty:name=``Brussels'']/@cty:name
which just returns ``Brussels'' which is also the answer
to (*)
XML Information Server Cooperation.
As already stated, the applicability of both strategies depends on the
services provided by the remote data source, cf. Section 6.2. As a
straightforward strategy, the client will first try to send the rewritten query
xpath-exprxl/xpath-exprq2 via
HTTP to the server at url where it will be answered
if the server is an XML database system. If the query is not
answered, the client will try to access the XML document, parse it
into its own database, and evaluate the query by itself. More
involved strategies that are tailored to the needs of a given
application are described in the following.
Next, we investigate the ``when'' aspect, i.e., if the result sets of
link elements should be prefetched when parsing an XML instance, or
if links are evaluated on demand.
5. Materializing and Prefetching Results
Similar to relational views, strategies for saving computational
effort when answering queries apply to the views induced by links.
Note that here, not only computational expenses (either at the local
or the remote server) may be saved, but also internet communication
can be reduced.
Since the required links are already known when parsing an XML
instance, already at this stage, the whole virtual tree can be
materialized locally: when the view is ``defined'' by parsing an XML
document, its extension can be computed (either at the local or the
remote server) and stored. Then, queries can be evaluated based on the
precomputed view. Note that even the whole remote XML instance can be
stored locally, which may reduce the internet communication in case
that there are several links that use the same url. In both cases,
no internet access is required at query answering time. On the other
hand, the actual evaluation of queries wrt. the materialized link
views must then be done locally wrt. the cached data.
Another possibility is to cache the answer when a query against the
remote source via a link is evaluated for the first time. Again,
either the view defined by the link (i.e., the result of
xpath-exprxl) can be materialized as a subtree
(and used later also for other queries), or the answer to a given
query (i.e.,
xpath-exprxl/xpath-exprq2}) is
stored, keeping the link subtrees virtual.
Similar to relational databases, if an answer or view is cached, the
consequence is that subsequent answers use the stored state instead of
the current state of the remote source. On the other hand, this
guarantees that all queries are evaluated wrt. the same state of the
remote source.
Summarizing, when querying links, several parameters should be
specifiable:
- when is the link evaluated (at parse time or at query answering
time),
- where does the computation take place (locally or at the remote
server), and
- which (intermediate) results should be stored and reused.
Furthermore, there are interferences between the above options. In the
subsequent section, we propose an extension to the xlink:
namespace that allows for specifying the behavior of links wrt.
querying. For these extensions, we use the dbxlink namespace
(denoting the database aspect of XLink).
6. Specification Parameters for Evaluating Links
XLink [XLink] defines several attributes for link elements
that specify the behavior of the link element, i.e.,
when it should become ``activated'' and what happens
then. In the current version, this behavior is tailored to the use of
links when browsing, it does not cover the requirements of querying
XML instances. As defined above, there are several aspects for
specifying the behavior of links wrt. querying:
- Activating Event: The activating event of links is considered
in XLink with the dbxlink:actuate attribute: the value
auto states that the link is activated when it is parsed,
whereas user states that it is activated by the user (HTML:
clicking).
In our context, auto means that the XPointer is evaluated
when the node containing it is parsed whereas user denotes
that it is evaluated when it is used by a query.
We add an dbxlink:actuate=``noaction'' alternative that does
nothing: the unresolved link remains -- as a kind of view
definition -- in the answer tree, but without the
dbxlink:actuate=``noaction'' attribute. The intention here is
that the application/user who stated the query should decide (and
possibly pay) by himself when to finally resolve the link.
Especially, information servers will use this alternative (thus,
returning unresolved links to be processed by the client).
- Evaluation: As described above, for the evaluation -- both the
evaluation of the link when parsing, or the evaluation of the link
together with the remaining query on demand -- there are several
possibilities:
- dbxlink:eval=``local'' means that the whole target
document is requested and
xpath-exprxl (when parsing) or
xpath-exprxl/xpath-exprq2
(when answering a query) is evaluated locally.
- dbxlink:eval=``distributed'' states that
xpath-exprxl is submitted to the remote
server, and the result (which is the view represented by the link)
is transferred. When a query is evaluated, the remaining
xpath-exprq2 is evaluated locally.
- Finally, dbxlink:eval=``remote'' means that
xpath-exprxl (when parsing) or
xpath-exprxl/xpath-exprq2
(when evaluating a query) is submitted to the remote server for
evaluation, and only the final result is transferred.
- dbxlink:eval is NMTOKENS, thus, combinations
like dbxlink:eval=``remote local'' mean that
first, it is tried to make the remote server answer the complete
query. If this fails, the document is requested and the evaluation
is done locally.
- Answer Caching: When computing the result or accessing the
target server (for the complete document), the obtained data may be
cached:
- dbxlink:cache=``complete'' parses the whole target
document (useful in case that there are many links to the
document, such that it makes sense to regard it as a part of the
database) and stores it (centrally) in the local XML database.
When later a query traverses the link, it has only to evaluate
xpath-exprxl on the already parsed document.
- dbxlink:cache=``transparent'' replaces the link by the
result set of
document(url)/xpath-exprxl (i.e.,
materializing the answer as in Example 9).
- dbxlink:cache=``answer'' stores the answer to a query
document(url)/xpath-exprxl/xpathq2,
against a remote source and keeps it somewhere in the database
(useful if the same link or query occurs several times).
- default is dbxlink:cache=``none''.
- dbxlink:cache is NMTOKENS, thus, combinations
like dbxlink:cache=``complete answer'' mean that the whole document
is cached (in case there are many links to it) and also the answers to
individual queries are cached.
Note that the caching specifications strongly depend on the
evaluation specifications: only such information can be cached that
is actually communicated to the server; on the other hand, caching
at rough granularity makes only sense if the information is actually
used by subsequent query evaluations:
- dbxlink:cache=``complete'' makes only sense for
dbxlink:eval=``local'',
- dbxlink:cache=``transparent'' (materializing the link view)
makes sense for dbxlink:eval=``local'' and
dbxlink:eval=``distributed''.
6.1 Runtime Behavior
The actual evaluation of links happens either when parsing a document
into the local XML database, or when answering queries.
Parsing
When parsing a document the links with dbxlink:actuate=``auto''
are evaluated and cached: If dbxlink:cache=``complete'', the
whole remote document is requested and parsed; if
dbxlink:cache=``transparent'', the view defined by the
individual link is materialized as a subtree. In the latter case, the
value of dbxlink:eval specifies where the actual computation of
document(url)/xpath-exprxl is carried
out. Note that links specified as dbxlink:cache=``answer''
cannot be precomputed at parse time, since there is not yet any query.
In the abstract data model, the resulting subtrees are replaced
for the link elements, but the actual implementation may store them
separately.
Evaluating Queries
When the database is actually used for evaluating queries, the answers
that have been cached either from parsing the document, or from
previous queries are reused. Specifying dbxlink:cache=``none''
disables caching for a query, e.g., when the remote data sources may
change and the current state is required. In other cases, either (i)
the link is evaluated against the cached document (for
dbxlink:cache=``complete''), or (ii) the materialized subtree
that replaced the link is used (for
dbxlink:cache=``transparent''), or (iii) the cached answer from
a previous evaluation of the same query is used. In all cases, the
cached data may also be stored from another query that uses the same
remote data source, link, or the same query against the link.
If there is not yet a precomputed answer (including the case
dbxlink:cache=``none''), the evaluation strategy given by
dbxlink:eval specifies how the answer is computed, and
according to dbxlink:cache, the intermediate or final results
are cached.
Possible Combinations.
The table given in below shows which
actions are necessary when a link is traversed the first time, and all
subsequent times for all possible combinations of specification
parameters.
The following strategies are the cornerstones of the spectrum:
- The strategy (dbxlink:actuate=``auto''
dbxlink:cache=``transparent answer'') guarantees the best
performance for the query answering tasks: all link views are
precomputed as transparent subtrees after parsing the document, and
later, also all answers are added to the cache.
- The strategies (dbxlink:actuate=``user''
dbxlink:cache=``none'' dbxlink:eval=``remote'') and
(dbxlink:actuate=``user'' dbxlink:cache=``answer''
dbxlink:eval=``remote'') are the ``leanest'' ones: only the
necessary computations are done (by the remote server). The first
variant does not cache anything (minimizing space, and always using
the current state of the remote data source), the second one caches
the answers (minimizing communication).
- On the other hand, specifying (dbxlink:actuate=``auto''
dbxlink:cache=``complete transparent'' dbxlink:eval=``local'')
makes the system as independent as possible from the remote source,
which is especially useful if transient sources are used, or if the
internet connection is not persistent.
|
dbxlink:actuate=``auto'' |
| dbxlink:eval x dbxlink:cache |
lc | lt | la | ln |
dt | da | dn |
ra | rn |
| use cached document |
33 | -- | -- | -- | -- | -- | -- | -- | -- |
| access remote document |
-- | -- | 9- | 99 | -- | -- | -- | -- | -- |
| add document to cache |
-- | -- | -- | -- | -- | -- | -- | -- | -- |
| use transparent subtree |
-- | 11 | -- | -- | 11 | -- | -- | -- | -- |
| compute link view remote |
-- | -- | -- | -- | -- | 1- | 11 | 1- | 11 |
| transfer link view |
-- | -- | -- | -- | -- | 4- | 44 | -- | -- |
| compute link view locally |
33 | -- | 3- | 33 | -- | -- | -- | -- | -- |
| replace link by subtree |
-- | -- | -- | -- | -- | -- | -- | -- | -- |
| use cached answer |
-- | -- | -1 | -- | -- | -1 | -- | -1 | -- |
| compute answer remote |
-- | -- | -- | -- | -- | -- | -- | 1- | 11 |
| transfer answer |
-- | -- | -- | -- | -- | -- | -- | 1- | 11 |
| compute answer locally |
22 | 22 | 2- | 22 | 22 | 2- | 22 | -- | -- |
| add answer to cache |
-- | -- | 1- | -- | -- | 1- | -- | 1- | -- |
|
dbxlink:actuate=``user'' |
| dbxlink:eval x dbxlink:cache |
lc | lt | la | ln | dt
| da | dn | ra | rn |
| use cached document | -3 | -- | -- | -- | -- | -- | -- | -- | -- |
| access remote document | 9- | 9- | 9- | 99 | -- | -- | -- | -- | -- |
| add document to cache | 3- | -- | -- | -- | -- | -- | -- | -- | -- |
| use transparent subtree |
-- | -1 | -- | -- | -1 | -- | -- | -- | -- |
| compute link view remote |
-- | -- | -- | -- | 1- | 1- | 11 | 1- | 11 |
| transfer link view |
-- | -- | -- | -- | 4- | 4- | 44 | -- | -- |
| compute link view locally |
33 | 3- | 3- | 33 | -- | -- | -- | -- | -- |
| replace link by subtree |
-- | 1- | -- | -- | 1- | -- | -- | -- | -- |
| use cached answer |
-- | -- | -1 | -- | -- | -1 | -- | -1 | -- |
| compute answer remote |
-- | -- | -- | -- | -- | -- | -- | 1- | 11 |
| transfer answer |
-- | -- | -- | -- | -- | -- | -- | 1- | 11 |
| compute answer locally |
22 | 22 | 2- | 22 | 22 | 2- | 22 | -- | -- |
| add answer to cache |
-- | -- | 1- | -- | -- | 1- | -- | 1- | -- |
| 1st entry: first time |
|
- : no action required |
| 2nd entry: all subsequent times |
|
n: action required (estimated cost: n) |
| Note that multigranularity caching (e.g., dbxlink:cache=``lcta'')
adds additional variants. |
| Also, previous operations may have cached useful information (e.g.,
pages) |
Figure 2: Required Actions when Traversing a Link
Using dbxlink:cache=``complete transparent'' provides a double
caching which is useful when the target document is referenced by
different XPointers, together covering large parts of the target
document, and each of the XPointers occurs in several links.
Note that the actual runtime behavior can also be influenced by
different specifications for different links in a document, e.g., when
another link already accessed the complete document or another link
has already precomputed the answer.
6.2 Constraints
In practice, the functionality which is provided by the remote servers
constrains the possible alternatives:
``Lazy'' Servers
If only a plain XML document (e.g., as ASCII) is provided, the client
that initiated the query has to access the document and evaluate the
XPointer expression by itself (dbxlink:eval=``local''). Then,
the client has to decide if he accepts the link strategies defined in
the document.
``Hiding'' Servers
If the referenced document is located on a server that does not
publish the whole document, but only answers queries,
dbxlink:eval=``local'' (and also
dbxlink:cache=``complete'') is not applicable.
Note that even servers that answer only a restricted set of XPath
queries are possible. In this case, it may be necessary to
rewrite queries according to the provided views.
Costs
Additionally, for the user of information services, the costs
associated with an information source are relevant:
- dbxlink:eval=``local'' (especially, without
dbxlink:cache=``complete'') requires transferring the
whole XML document may be expensive when the costs depend on the
size of data,
- Any strategy without dbxlink:cache=``complete'' may be
expensive when the costs depend on the number of queries,
especially, if no caching at all is used.
- dbxlink:eval=``remote'' is expensive wrt. the remote
computation time, especially, if the answers are not cached.
- Obviously, dbxlink:cache=``none'' is potentially
expensive in all cases: with dbxlink:eval=``local'', the
transferred volume is excessive (always, the whole XML documents are
transferred), and with dbxlink:eval=``remote'', the remote
computation time can be considerable.
So far, the strategies have been investigated from the point of view
of the ``client''.
6.3 Information Providers
For an information provider, dbxlink:actuate=``noaction''
assures that he will not have any effort (neither computational
resources, nor costs) for resolving the links in the documents he
provides. Obviously, then, the provider is not able to answer XPath
queries, not only because of his decision not to have any expenses
wrt. computational resources, but also since the links in the
documents are opaque for him. The provider must deny any access with
dbxlink:eval=``remote'' and dbxlink:eval=``distributed''
(hopefully, the client specified a fallback to
dbxlink:eval=``local'' for links pointing to this server).
Thus, clients may only access the whole XML document and to provide an
overriding specification for dbxlink:actuate=``noaction'' how
to handle links (pointing to third party documents) in this document.
6.4 Data Model
Regarding the views defined by links as subtrees that replace the
original link element, the data model, i.e., the definition of the
tree, must be ``continued'' with these subtrees. Here, an important
decision is whether the elements of the subtree are full descendants
wrt. the // operator:
- Descendants strategy: XLink does not address this issue. We
propose an additional attribute dbxlink:descendants that
can be used to specify if the link should be transparent wrt. the
descendant axis:
- the link itself may specify if it wants to be transparent
wrt. the descendants relation (``yes''/``no''),
- the application may specify which elements in virtual
subtrees resulting from transparent links are regarded as
descendants: all, none, sameserver
(those resulting from links where the target url is on the same
server as the source url), or predefined (use the
strategy given by the link).
When a link is specified with dbxlink:descendants=``yes'',
and dbxlink:descendants=``all'' is specified by the
application, the link must be considered whenever it is involved in a
descendant navigation step. Thus, it is often preferable to
materialize it, or to use additional metadata information to check if
it may yield relevant answers (see below).
Referential Integrity.
Another problem -- which is in
some sense concerned with the data model -- is the maintenance of
referential integrity in an interlinked network of sources: links are
expected to point to one or more elements that have a certain
connection to the parents of the link elements (e.g., the seats of
organizations). Here, the xpath-exprxl
query part of the link has to use values for identifying these
elements. In the relational model, this is done using keys,
leading to the well-known referential integrity maintenance issues.
Since XML Schema also provides a notion of keys and key references,
these are natural candidates for use in link references. Thus, it is
likely that similar problems will arise.
6.5 Optimizations and Perspectives
Resource Descriptions
If the provider of a referenced XML document also provides a
resource description, it is often even possible to decide a
priori whether the actual query may be successful.
Especially, when links are regarded as transparent wrt. the
descendant axis, for expressions of the form
...//nodetest, the simple information whether the linked
document can contain elements that satisfy the nodetest
can save the expense of querying the linked data source.
Example 11
The XPath expression
document(``mondial-countries'')//inflation (which selects
all inflation elements by following the links to all
documents described above) does not need to follow the links to the
city documents since these do not contain any
inflation element.
With a more detailed metadata description, e.g., in RDF
(Resource Description Format), the evaluation of many queries can be
optimized.
XML-Aware Web Caches
In the context of frequently used remote information sources, the
current ``local'' caching may create redundant cached copies of views.
An obvious optimiziation is to use caches at the remote servers that
store the results of frequent queries.
Another possibility is to use XML-aware caches technology in the Web
which allows to store (url,query,answer) tuples that occur frequently.
In contrast to the above alternative, this can -- at least in a
restricted way -- be implemented by the user, e.g., in a proxy server
for his company. This approach is e.g. investigated in
[LM01].
7. LoPiX
Currently, the LoPiX system [LoPiX, May01a] is used for investigating
the handling of links in an XPath-based environment. LoPiX is an
environment for using XPathLog (an extension of XPath, see [May01b] as
a language for XML data integration. LoPiX (cf. Figure 3) consists of
a central XPathLog evaluation engine, a storage module that implements
the internal data model, an Internet access module, and an optional
XML/XPath interface for electronic data interchange with external
XML-based systems. For the present paper, the data-driven Web access
functionality and its transparent resolving of links is relevant.
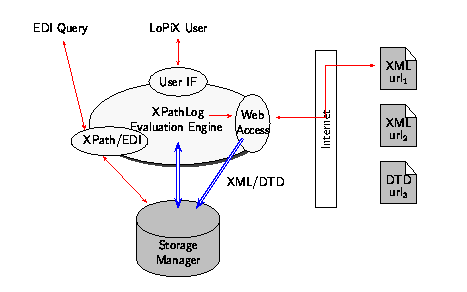
Figure 3: LoPiX Architecture
The internal database can be extended by new XML documents depending
on information and links (i.e., pure urls or links) found in already
known documents: Whenever for some url url, the
built-in active method url.parse@(xml) is called,
the document located at url is automatically loaded
as an XML tree. All link elements with
dbxlink:actuate=``auto'' are preprocessed according to the
values of dbxlink:cache and dbxlink:eval.
When a navigation step traverses a link element such that
dbxlink:actuate=``user'', the link is evaluated according to
the values of dbxlink:cache and dbxlink:eval. Thus, when
querying linked XML sources, the actual query syntax is independent
from the values of dbxlink:actuate, dbxlink:cache, and
dbxlink:eval since these specifications are completely handled
by the evaluation component.
8. Conclusion
Related Work.
In contrast to, e.g., the relational model or
previous semistructured data models, XML and XLink provide a construct
for seamless integration of view definitions into the data
via links. This semantics raises new aspects for querying
languages. Nevertheless, the most prominent ones, i.e., XML-QL
[DFF+99], and Quilt/XQuery [CRF00,XQuery], do not support
links as defined by XLink. XSLT [XSLT] allows for handling links by
special patterns (to be specified manually).
Conclusion.
Querying distributed XML documents on the Web
by declarative languages requires a more detailed specification of
xlink-related attributes. Above, we described what attributes
concerning evaluation time and place and result caching could be
added favorably to the XLink language. We investigated possible
semantics and strategies for handling them in a declarative query
language. As a result, we propose a ``transparent'' semantics for
XLink elements, similar to views. Especially when information sources
are used that can answer XPath queries on their contents, on-demand
resolving of links can be used to minimize the answer and to exploit
the server-side optimization in an optimal way.
In addition to a proposal how to handle links in XML querying
frameworks, we have identified the following areas for further
investigations: (i) XML/XPath query rewriting, (ii) XML-aware Web
caches, and (iii) intra-document and intra-source referential
integrity maintenance.
References
[CRF00] D. Chamberlin, J. Robie, and D. Florescu.
Quilt: An XML Query Language for Heterogeneous Data Sources.
In WebDB 2000, pp. 53-62, 2000.
[DFF+99]
A. Deutsch, M. Fernandez, D. Florescu, A. Levy, and D. Suciu.
XML-QL: A Query Language for XML.
In 8th. WWW Conference, 1999.
World Wide Web Consortium Technical Report, NOTE-xml-ql-19980819,
www.w3.org/TR/NOTE-xml-ql.
[LM01]
P. J. Marrón and G. Lausen.
On Processing XML in LDAP.
In Intl. Conf. on Very Large Data Bases (VLDB), 2001.
[LoPiX] The LoPiX System.
http://www.informatik.uni-freiburg.de/~may/lopix/.
[May01a] W. May.
LoPiX: A System for XML Data Integration and Manipulation.
In Intl. Conf. on Very Large Data Bases (VLDB),
Demonstration Track, 2001.
[May01b] W. May.
XPath-Logic and XPathLog: A Logic-Based Approach for Declarative XML
Data Manipulation.
Habilitation Thesis, Universität Freiburg, Institut für
Informatik, 2001.
Available from
http://www.informatik.uni-freiburg.de/~may/lopix/.
[Mondial]
The Mondial Database.
http://www.informatik.uni-freiburg.de/~may/Mondial/.
[XLink]
XML Linking Language (XLink) Version 1.0. W3C Recommendation.
http://www.w3.org/TR/xlink, June 2001.
[XMLQDM]
XQuery 1.0 and XPath 2.0 Data Model. W3C Working Draft (work in progress).
http://www.w3.org/TR/query-datamodel, June 2001.
[XPath]
XML Path Language (XPath) Version 1.0. W3C Recommendation.
http://www.w3.org/TR/xpath. Version 1.0 (1999) and 2.0 (2001).
[XPtr]
XML Pointer Language (XPointer) Version 1.0. W3C Candidate Recommendation.
http://www.w3.org/TR/xptr, Sept. 2001.
[XQuery]
XQuery: An XML Query Language (Version 1.0). W3C Working Draft
(work in progress).
http://www.w3.org/TR/xquery, June 2001.
[XSLT]
XSL Transformations (XSLT) Version 1.0. W3C Recommendation.
http://www.w3.org/TR/xslt, Nov. 1999.