Existing XML query languages do not support ranked query
results based on textual similarity. For example,
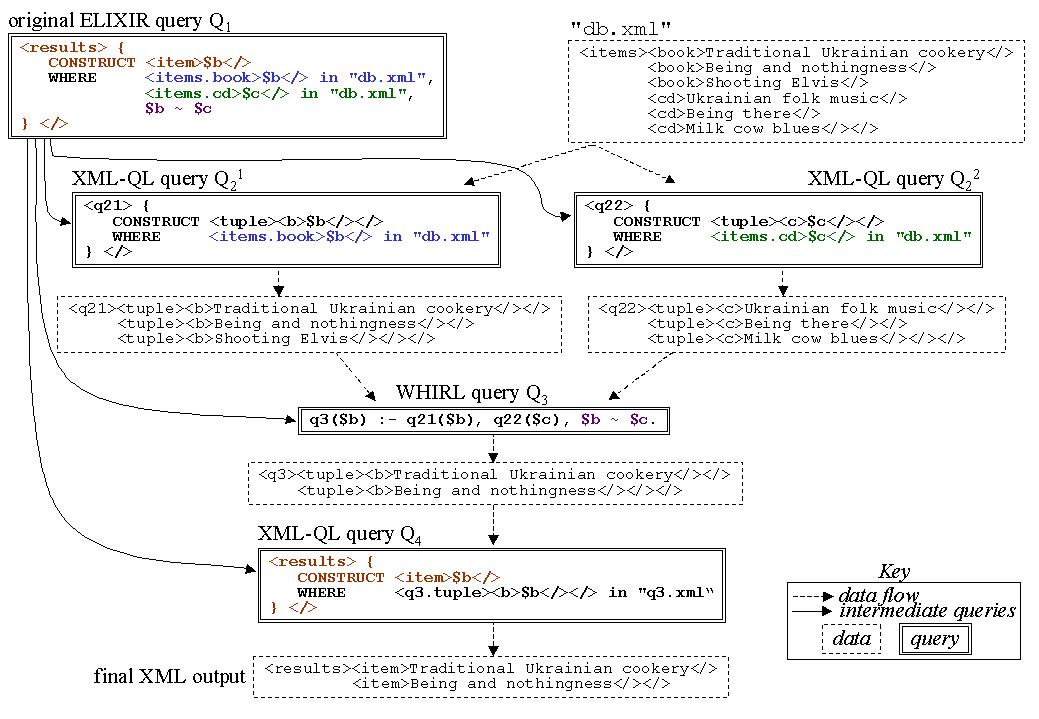
Fig. 1 shows an XML database containing books
and CDs. We are interested in information-retrieval-style queries
such as ``order the items by similarity to the phrase `traditional
Ukrainian''' or ``find books and CDs with similar titles.
Unlike similar efforts, our expressive and efficient
language for XML information
retrieval (ELIXIR) allows such queries. ELIXIR extends XML-QL [3] with a textual similarity operator. Fig. 1 shows an ELIXIR query Q1 that finds books and CDs with similar titles. Some related query languages (e.g. [5, 7]) provide only boolean keyword filtering, not ranked retrieval based on textual similarity. Other languages (e.g. [6, 9]) permit similarity comparisons only between a data value and a constant, but not similarity joins across two data values, and thus cannot express Q1.

A more complicated ELIXIR query is shown in Fig. 2. As can be seen from the output, this query finds recent SIGMOD Record publications, New Testament verses, and lines from Macbeth that are similar.
Similarity joins are not merely of theoretical interest. For example, in data integration applications involving reconciling heterogeneous textual identifiers, similarity joins can eliminate the need for either common domains or hand-crafted normalization routines.
A naive implementation of a similarity join between two variables would generate the full cross product of the variable bindings, and then compute the similarity of every pair. Our ELIXIR query processing algorithm avoids this pitfall by:
Note that ELIXIR queries XML data in its native format, without the potentially expensive operation of flattening it into relations [4, 8].
Fig. 1 shows how the ELIXIR query processing would rewrite Q1 into a series of XML-QL queries Q2i, a WHIRL query Q3, and a final XML-QL query Q4. Also shown are the intermediate data that would be passed between the queries, and the final XML output. The algorithm first generates two XML-QL Q2i queries. Q21 retrieves books from the XML database, and Q22 retrieves CDs. Note that ELIXIR retrieves these items separately to avoid computing the cross product of book/CD pairs. The algorithm then generates the WHIRL query Q3, which applies Q1's similarity predicate. Q3's output is the desired result, but it is transformed into XML format by executing Q4.
ELIXIR's query rewriting algorithm runs in time polynomial in the size of the query, and thus ELIXIR's additional functionality adds negligible overhead to the cost of the underlying XML-QL and WHIRL implementations. Experiments with our ELIXIR prototype demonstrate that our query processing algorithm scales reasonably well with respect to the size and complexity of an ELIXIR query, the size of the intermediate data generated by WHIRL, and the number of similarity-join predicates.
Our implementation of ELIXIR extends XML-QL, but we are currently exploring ways of extending the ELIXIR algorithm to other XML query languages such as Quilt [1]. Another area of future research is query optimization. The ELIXIR query processor follows a strict three-stage policy for rewriting the original query, but this may be sub-optimal in some cases. We are exploring techniques for automatically searching the space of query rewritings in order to find one that is optimal with respect to standard metrics such as intermediate data sizes.
More information can be found on http://www.smi.ucd.ie/elixir