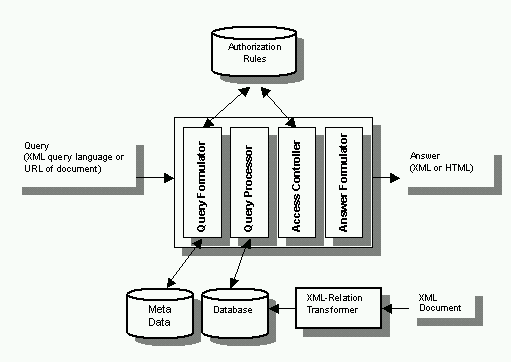
Figure 1: Architecture of XENA.
Yue Wang
Department of Computer Science
National University of
Singapore
Science Drive 2, Singapore 117543
wangyue@comp.nus.edu.sg
Kian
Lee Tan
Department of Computer Science
National University of
Singapore
Science Drive 2, Singapore 117543
tankl@comp.nus.edu.sg
Keywords: XML, access control, relational database, scalable.
In recent years,there is an increasing amount of information being distributed and shared in XML format over coporate Intranets and the global Internet. As a result, it becomes critical to define and enforce access restrictions on XML documents to ensure that only authorized users have access to the information. Clearly, the simple method of protecting an entire document at the file level is unattractive (since it will limit the dissemination of information) and unnecessary (as different users may be allowed to access different portions of the document).
One promising access control model proposed in the literature is to enforce
access restrictions directly on the structure and content of XML documents [1,2]. In this way,
information in XML format can be protected at a finer level of graularity than
the whole document, e.g., at the tag level. As an example, a user may be blocked
from accessing information tagged by XLink and
XPointer, while another may be allowed to access the entire
document.
The design of an access control systems based on this model were reported in [1,3]. The systems essentially represent XML documents as object trees, according to the Document Object Model (DOM) Level 1 specification [6]. DOM provides an object-oriented Application Program Interface (API) for HTML and XML documents. To enforce security, the DOM tree is repeatedly traversed to mark out nodes that should be denied access. This step is done based on the authorization rules for the user. Finally, the DOM tree is traversed to prune away the nodes that are marked, and the remaining DOM structure represents information that can be accessed by the user. This architecture has two main problems. First, it requires the entire DOM tree to be memory resident. This problem is exacerbated by the fact that a DOM tree is typically much larger (about 5 to 10 times) than its XML document. Thus, the scheme is not scalable for large XML documents. Second, the initial response time is long. This is because all the steps must be completed before any answers are returned to the user. Third, the scheme is inefficient. This is because the DOM tree has to be repeatedly traversed and its nodes labeled. More importantly, a lot of unnecessary information is also loaded (in the sense that the system loads the entire XML document and then prune away information that should not be disclosed.). To overcome these limitations, novel design of access control systems is necessary.
In this paper, we present the design of an access control system, XENA (Xml sEcurity eNforcement Arctecture), that we are currently implementing at the National University of Singapore.
XENA has several characteristics that are desirable for a secure system for XML documents:
To store XML documents as tables, we need to map the content of XML documents into tuples of tables. In this work, we have adopted the XStorM mapping strategy [5]. XStorM employs a data-mining strategy to identify relations and their attributes. Note that a single XML file can be mapped into multiple tables. In other words, we may need to join multiple tables to produce the original XML document. Since our focus is not on the mapping strategy here, and due to space constraint, interested readers are referred to [5] for further details.
Figure 1 shows the architecture of XENA. Initially, all XML documents are mapped into relational tables by the XML-Relation Transformer module. The process also maintains the mapping information in the metadata database, including the correspondences between the XML document objects and the relation names, and the XML document attributes and the relation attributes. New documents are preprocessed and added in a similar manner.
When a query arrives, the Query Formulator parsed the query and maps it into an internal query. Th module essentially examines the authorization rules and the metadata corresponding to the requested documents, and produces a query that will retrieve only those information that can be accessed by the requester. For example, if the requester is not allowed to see a certain attribute, then this attribute will be filtered out (by not specifying it in the target list) so that it is not necessary to access it from the database. Similarly, those tuples that the requester are not allowed to access are also filtered out (by introducing a selection predicate to prune them away).
The internal query is then evaluated by the Query Processor. This module accesses the data from the database according to the internal query, i.e., only the relevant information will be accessed.
Note that the requester may still not be able to view all the retrieved data. This is because there may be special cases that cannot be handled by the Query Formulator. For example, the requester may be allowed to view attributes A, B and C. However, (s)he is not allowed to look at those tuples whose B values are say 5, 14, 27 and 39. Note that while we can introduce selection predicates on B, this may be very tedious if the list of exceptions are not small and does not follow any pattern. As such, it may be easier to allow them to be accessed first, and then prune away later. This is exactly the task of the Access Controller module. It basically applies the set of authorization rules that cannot be enforced by the Query Formulator.
Finally, the Answer Formulator formulates the output in a form (e.g., XML or HTML) for the requester. We note that XENA only allows the users to view what (s)he is allowed to access and nothing else.
We have implemented and evaluated most of the components independently. We expect the full system to be integrated within the next few months. Our preliminary experience with the various components have been good. For example, XStorM shows that storing XML documents as tables can cut down the total response time significantly compared to accessing the entirety of the XML docucments. In particular, as soon as one answer is retrieved, it can be returned to the requester. The access control model can also correctly grant and deny accesses.
This work is partially supported by a research grant funded by the National University of Singapore and the National Science and Technology Board. We would like to thank the authors of [1] for providing us with their source code. This allows us to reuse a large part of the code in our implementation while we convert to XML schema (instead of DTD).