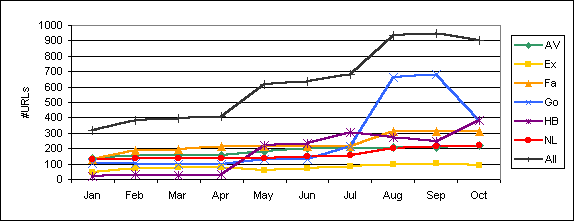
Figure 1: URLs per search round and search engine
A document is defined to be technically relevant if it fulfills all the conditions posed by the query: all search terms and phrases that suppose to appear in the document do appear, and all terms and phrases that are supposed to be missing from the document - terms preceded by a minus sign or a NOT operator, do not appear in the document. Technical precision is defined as the percentage of technically relevant retrieved documents out of the total number of retrieved documents.
The set of well-handled URLs is defined as the URLs that are either continuously retrieved by the engine from the first time they was discovered by it, or if the URLs are not retained by the search engine, it is because they either disappeared from the Web or cease to be technically relevant.
The set of mishandled URLs is the set of URLs that disappeared from the search results during the search period (such URLs are counted with multiplicity one even if they were "forgotten" several times), even though the URLs continued to exist and continued to be technically relevant. The set of mishandled URLs can be further partitioned into the set of mishandled reappeared URLs (these are URLs which disappeared from the search results at one stage, but reappeared later) and the set of mishandled disappeared URLs, which are mishandled URLs that never reappeared at a later stage.
Figure 1: URLs per search round and search engine
The technical precision of the search engines was rather high between 76.3% and 99.5%. Excite and Hotbot had the highest technical precision. Note that besides pages not containing the search term, unreachable URLs and documents not found (404 errors) were also categorized as technically irrelevant.
Figure 2 depicts the extent to which each search engine mishandled URLs during the search period.
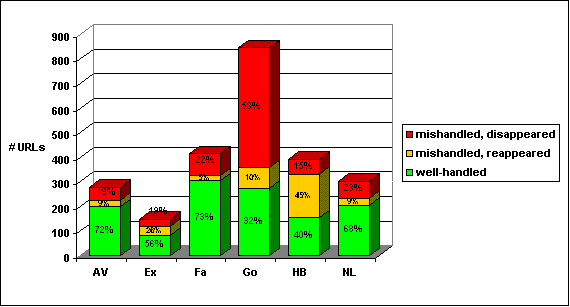
Figure 2: Well
handled and mishandled URLs over the search period
4. CONCLUSIONS
The example illustrates that there is a need to study search engine stability (or rather instability) over time.